DQN Maze Solver
In the previous tutorial I showed how to build a maze-solving Q-learner using a table-based Q-learning method. In this post, I show how to solve the same maze using DQN (Deep Q-Learning). The code for this example program is found here.
While the table-based approach is ideal for small state spaces (869 bytes for 6 states), DQN replaces the Q-table with a neural network, enabling reinforcement learning in environments with hundreds or thousands of states where a Q-table would be prohibitively large. The entire DQN implementation here – neural network, Q-learning logic, and lookup tables – fits in under 16 KB. In standard frameworks like PyTorch or TensorFlow, a DQN of any size requires tens of megabytes of runtime before the first weight is allocated.
Reinforcement Learning
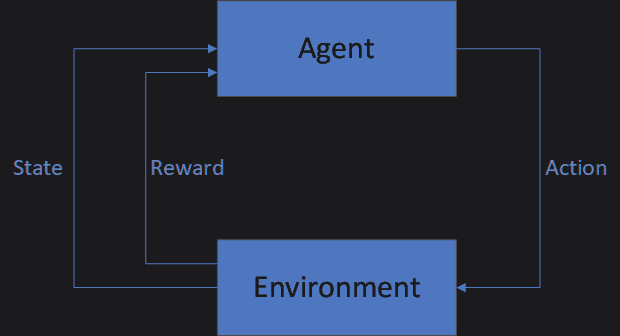
In a reinforcement learning problem, an Agent interacts with an Environment by evaluating its State, taking Actions, and receiving Rewards. The goal is to learn which Actions provide the most Reward over the course of time.
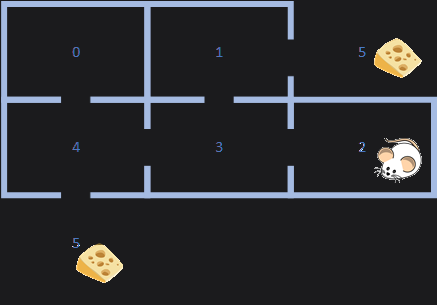
The Maze Problem
As in the previous tutorial, we’re going to attempt to solve the maze problem. A mouse gets dropped randomly into 1 of 6 places on the maze and must learn to find the cheese (reward).
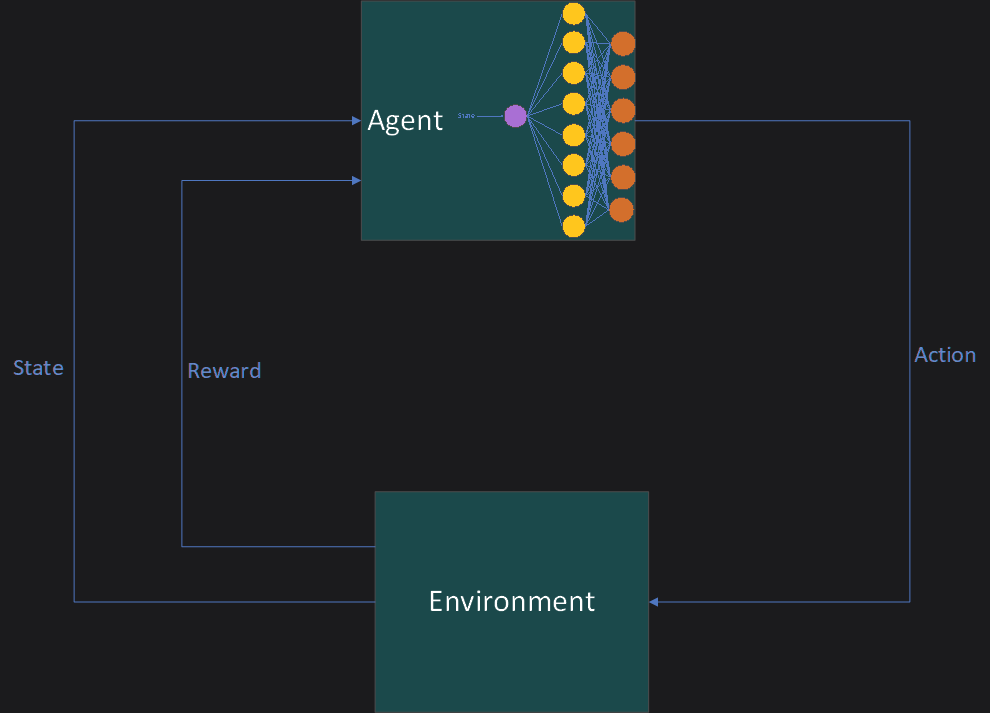
DQN Architecture
For this problem we will get rid of the Q-table and replace it with a neural network. We will need 1 input neuron (State) and 6 output neurons (Actions). I’ve chosen to implement 1 hidden layer with 2 more neurons than output neurons.
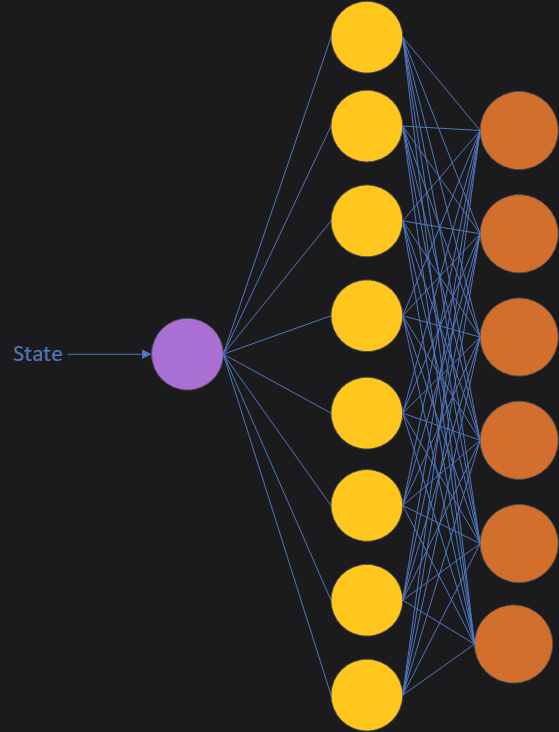
Each output neuron represents the action to take from the state. There is 1 neuron in the input layer, which represents the current state of our mouse. Using Q-format, I scale the input by taking the current state and dividing by the maximum possible state:
template<typename StateType,
typename ActionType,
typename ValueType,
size_t NumberOfStates,
size_t NumberOfActions,
typename RewardPolicyType,
template<typename> class QLearningPolicy = tinymind::DefaultLearningPolicy
>
struct DQNMazeEnvironment : public tinymind::QLearningEnvironment<state_t, action_t, ValueType, NumberOfStates, NumberOfActions, DQNMazeEnvironmentRandomNumberGeneratorPolicy>
{
...
static void getInputValues(const StateType state, ValueType *pInputs)
{
static const ValueType MAX_STATE = ValueType((NumberOfStates - 1),0);
ValueType input = (ValueType(state, 0) / MAX_STATE);
*pInputs = input;
}
DQN Neural Network
The neural network is trained to predict the Q-value for every action taken from the given state. After the neural network is trained, we then choose the action which contains the highest Q-value. See the Neural Networks page and the Under 4KB tutorial for more insight into how these neural networks work.
The DQN is defined within dqn_mazelearner.h.
Building The Example
cd examples/dqn_maze
make
Run the example:
make run
Visualizing Training And Testing
I have included a Python script to plot the training and test data.
Training data for start state == 2:
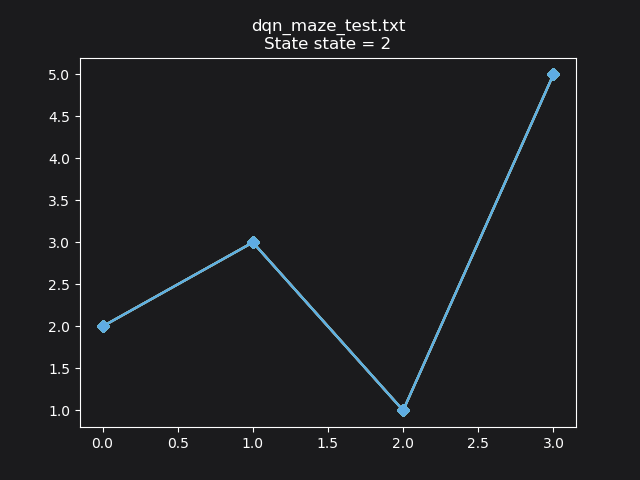
After training, the Q-learner has learned an optimal path: 2->3->1->5:
Determining The Size Of The DQN
make release
size output/dqn_mazelearner.o
text data bss dec hex filename
10979 8 3652 14639 392f output/dqn_mazelearner.o
The entire DQN fits within ~16 KB. Pretty small as DQN goes.
Conclusion
DQN trades out the Q-table for a neural network to learn the relationship between states, actions, and Q-values. One would want to use DQN when the state space is large and the memory consumed by the Q-table would be prohibitively large. By using DQN, we’re trading memory for CPU cycles. The CPU overhead for DQN will be far larger than a Q-table. But, DQN allows us to do Q-learning while keeping our memory footprint manageable for complex environments.