Table-Based Q-Learning in Under 1KB
Q-learning is an algorithm in which an agent interacts with its environment and collects rewards for taking desirable actions.
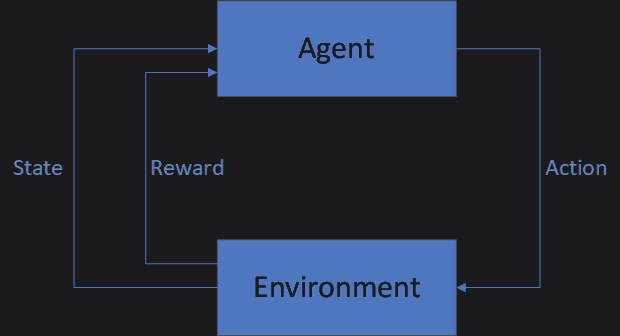
The simplest implementation of Q-learning is referred to as tabular or table-based Q-learning. In this article, I will describe how tinymind implements Q-learning using C++ templates and fixed-point (Q-Format) numbers as well as go through the maze example in the tinymind repo.
At 869 bytes total, this Q-learner fits comfortably on even the smallest microcontrollers – an ARM Cortex-M0+ with 4 KB of RAM has room for this plus the full application. Reinforcement learning is typically associated with cloud computing and massive compute budgets, but tinymind brings it to the edge with zero runtime overhead and no floating-point requirement.
The Maze Problem
A common table-based Q-learning problem is to train a virtual mouse to find its way out of a maze to get the cheese (reward). Tinymind contains an example program which demonstrates how the Q-learning template library works.
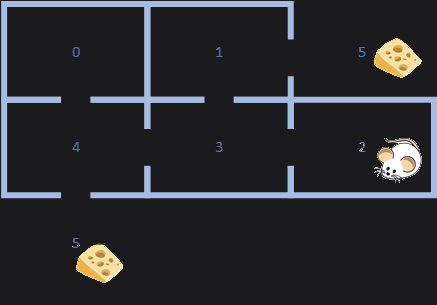
In the example program, we define the maze:
5 == Outside the maze
________________________________________________
| | |
| | |
| 0 | 1 / 5
| | |
|____________/ ________|__/ __________________|_______________________
| | | |
| | / |
| 4 | 3 | 2 |
| / | |
|__/ __________________|_______________________|_______________________|
5
The paths out of the maze:
0->4->5
0->4->3->1->5
1->5
1->3->4->5
2->3->1->5
2->3->4->5
3->1->5
3->4->5
4->5
4->3->1->5
We define all of our types in a common header so that we can separate the maze learner code from the training and file management code:
// 6 rooms and 6 actions
#define NUMBER_OF_STATES 6
#define NUMBER_OF_ACTIONS 6
typedef uint8_t state_t;
typedef uint8_t action_t;
We train the mouse by dropping it into a randomly-selected room. The mouse starts off by taking a random action from a list of available actions at each step. The mouse receives a reward only when he finds the cheese (makes it to position 5 outside the maze).
Building The Example
cd examples/maze
make
Run the example:
make run
Visualizing Training And Testing
I have included a Python script to plot the training and test data:
make plot
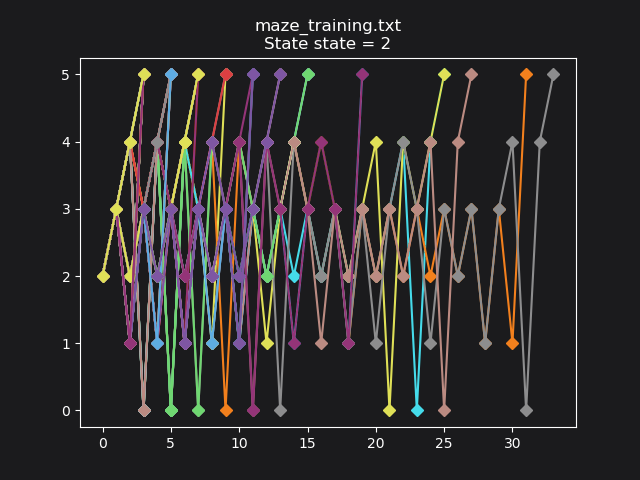
Training data for start state == 2 (random exploration):
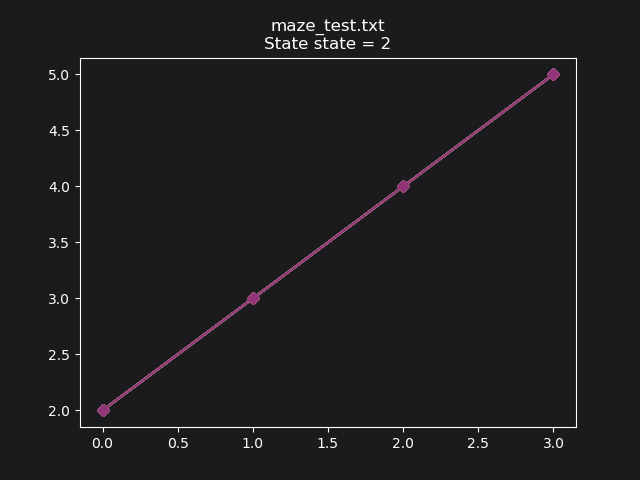
After training, the Q-learner has learned an optimal path: 2->3->4->5:
What happens when we drop the virtual mouse outside of the maze where the cheese is? During training:
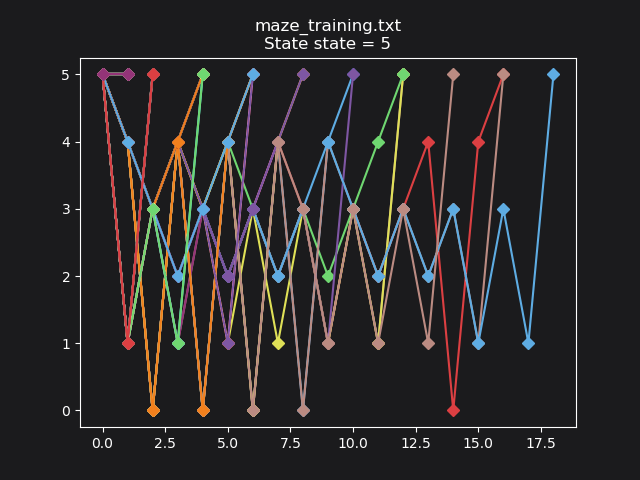
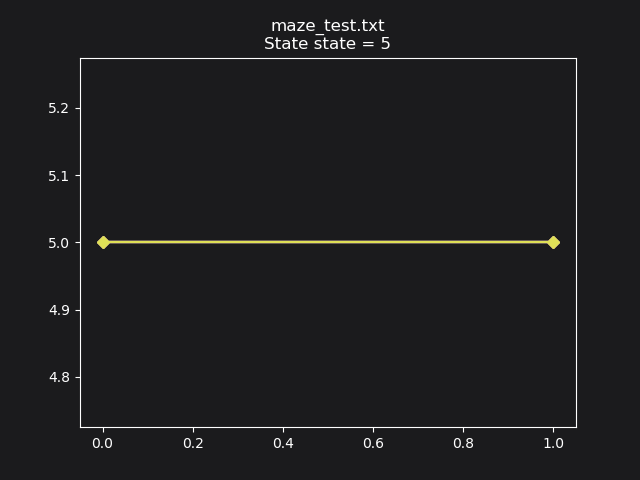
After training, the mouse has learned to stay put and get the reward:
Determining The Size Of The Q-Learner
make release
size output/mazelearner.o
text data bss dec hex filename
493 8 348 849 351 output/mazelearner.o
The total code + data footprint of the Q-learner is 869 bytes. This should allow a table-based Q-learning implementation to fit in any embedded system available today.
Conclusion
Table-based Q-learning can be done very efficiently using the capabilities provided within tinymind. We don’t need floating point or fancy interpreted programming languages. One can instantiate a Q-learner using C++ templates and fixed point numbers. Clone the repo and try the example for yourself!