Mixture of Experts
TinyMind provides a Mixture-of-Experts (MoE) layer family: a small router network scores the input against several expert sub-networks, and only the selected expert(s) run. The headline property for embedded targets is that compute and memory decouple – of N resident experts, only k run per inference, so active compute scales with k while modeled capacity scales with N.
| Variant | Header | Type | Experts run / call |
|---|---|---|---|
MixtureOfExperts | cpp/moe.hpp | float / QValue | 1 (top-1 argmax) |
TopKMixtureOfExperts | cpp/moe.hpp | float (FLOAT && STD) | k (softmax-gated) |
QMixtureOfExperts | cpp/qmoe.hpp | int8 affine | 1 (top-1 argmax) |
QTopKMixtureOfExperts | cpp/qmoe.hpp | int8 affine | k (gate via exp-LUT) |
Why MoE on a microcontroller?
A dense network pays for all of its weights on every inference. MoE breaks that link:
- Active compute / activation SRAM = one expert (top-1) + the tiny router. Same per-inference cost as a single small MLP.
- Resident flash = the router plus all experts. The router can pick any expert per input, so every expert must be in flash.
That makes MoE the right tool when flash is plentiful but cycles/energy are the bottleneck and the task is heterogeneous – distinct input regimes a router can separate (different motion classes, acoustic conditions, operating points). It is the wrong tool when flash is the binding constraint: there a single distilled dense MLP of equal flash wins, because MoE “spends” flash on experts that do not run.
There is no expert offloading: on bare metal there is nothing to stream experts from at inference speed, so all experts stay resident and N stays small (typically 2-4).
Top-1 routing: the embedded sweet spot
Top-1 (Switch-style) routing is the cheapest and most quantization-robust form, and it is the one to reach for first:
logits = router(x) // one scalar per expert
e* = argmax(logits) // pick the single best expert
y = expert[e*](x) // run only that expert
Two facts make this ideal for int8:
- No softmax is needed to choose.
argmaxover the raw logits is identical toargmaxover their softmax (softmax is monotonic). SoQMixtureOfExpertskeeps the router accumulator in int32 and never requantizes it – it just compares. - The decision is robust to quantization noise. int8 rounding can only flip the choice on a near-tie, and a near-tie means the two experts produce similar outputs anyway. A softmax-weighted blend, by contrast, would propagate router quantization error directly into the output.
Float example
#include "moe.hpp"
// 8 inputs -> 4 outputs, 3 experts. Default expert is LinearExpert.
tinymind::MixtureOfExperts<double, 8, 4, 3> moe;
// ... load router + expert weights (e.g. from offline training) ...
double input[8];
double output[4];
moe.forward(input, output);
size_t which = moe.getLastSelectedExpert(); // which expert fired
Experts are pluggable: the last template argument is a layer template taking <ValueType, InputDim, OutputDim>, defaulting to the built-in LinearExpert. Any layer adapted to that shape (a small MLP wrapper, Conv1D, SelfAttention1D, …) can serve as an expert; the only contract is a forward(input, output) and static InputSize / OutputSize equal to the MoE’s dimensions.
Int8 example
#include "qmoe.hpp"
typedef tinymind::QMixtureOfExperts<
int8_t, int8_t, int32_t, int8_t,
/*NumInputs=*/8, /*NumOutputs=*/4, /*NumExperts=*/3> MoE;
MoE moe;
moe.router_weights = router_w; // int8 [NumExperts * NumInputs]
moe.router_biases = router_b; // int32 [NumExperts] (or nullptr)
moe.input_zero_point = in_zp;
for (size_t e = 0; e < 3; ++e)
{
moe.experts[e].weights = expert_w[e];
moe.experts[e].biases = expert_b[e];
moe.experts[e].input_zero_point = in_zp;
moe.experts[e].requantizer = buildRequantizer<int8_t>(
in_scale, expert_w_scale[e], out_scale, out_zp, -128, 127);
}
int8_t input[8];
int8_t output[4];
size_t selected = moe.forward(input, output); // returns the expert index
Like every int8 layer in TinyMind, QMixtureOfExperts is caller-owned and pure integer at runtime – no float, no <cmath>, no stdlib – so it compiles in the freestanding FLOAT=0 / STD=0 / QUANT=1 configuration.
Quantizing an MoE
MoE adds no new quantization machinery beyond what the int8 layer family already has – it is “N independently-calibrated quantized experts + one quantized linear router.” Two rules:
- Per-expert weight scale. Each expert is calibrated independently so it can use the full int8 range for its own weights; experts often differ in dynamic range.
- One shared output scale. All experts requantize into a single output scale / zero point. The MoE output feeds one downstream consumer, so the int8 bytes must mean the same real value regardless of which expert produced them.
The router can stay int8 – argmax tolerates the noise – and needs no requantizer at all for top-1.
Top-k and dense MoE
When a use case wants a blended output, TopKMixtureOfExperts (float) and QTopKMixtureOfExperts (int8) run the K highest-scoring experts and return their gate-weighted sum:
topk = indices of the K largest logits
g_i = softmax(logits)_i over i in topk
y = sum_{i in topk} g_i * expert_i(x)
K = 1 collapses back to top-1 (gate 1.0); K = NumExperts is a dense MoE where every expert runs. The int8 path keeps top-k selection on the raw int32 logits (scale-invariant), but the gate weights need a real softmax, so the selected logits are requantized to int8 and run through an exp lookup table (buildQSoftmaxExpLUT, shared with QSoftmax1D); the experts’ int8 outputs are then blended in fixed point over the shared output scale.
#include "moe.hpp"
// Dense MoE: K == NumExperts. K=2 of 4 would be sparse top-2.
tinymind::TopKMixtureOfExperts<float, 8, 4, /*NumExperts=*/4, /*K=*/2> moe;
moe.forward(input, output);
float g0 = moe.getGate(0); // gate of the top expert
size_t e0 = moe.getSelectedExpert(0);
The float top-k layer computes its softmax in double, so it is gated on TINYMIND_ENABLE_FLOAT && TINYMIND_ENABLE_STD and intended for float/double value types; the int8 layer is the deployable, freestanding counterpart.
Deployment workflow
The intended flow is train-in-PyTorch, deploy int8: only the frozen router and expert weights ship. Load-balancing auxiliary losses, routing noise, and capacity factors are all training-time concerns and are dropped at conversion.
The apps/import_pytorch importer has an MoE descriptor that calibrates a float model and emits a weights.hpp with per-expert weight scales, the shared output scale, and a router with no requantizer (top-1). See the example below for an end-to-end round trip.
Examples
examples/moe_regimes_int8– int8 top-1 showcase. A linear router auto-partitions the input domain into three regimes, each handled by one linear expert approximating a nonlinear target.make benchprints the active-vs-resident accounting;make plotrenders the routing map.examples/import_moe_demo– importer round trip. A numpy float model is calibrated and emitted; the C++ binary consumes the generatedweights.hpp, rebuildsQMixtureOfExperts, and checks parity against the float reference.
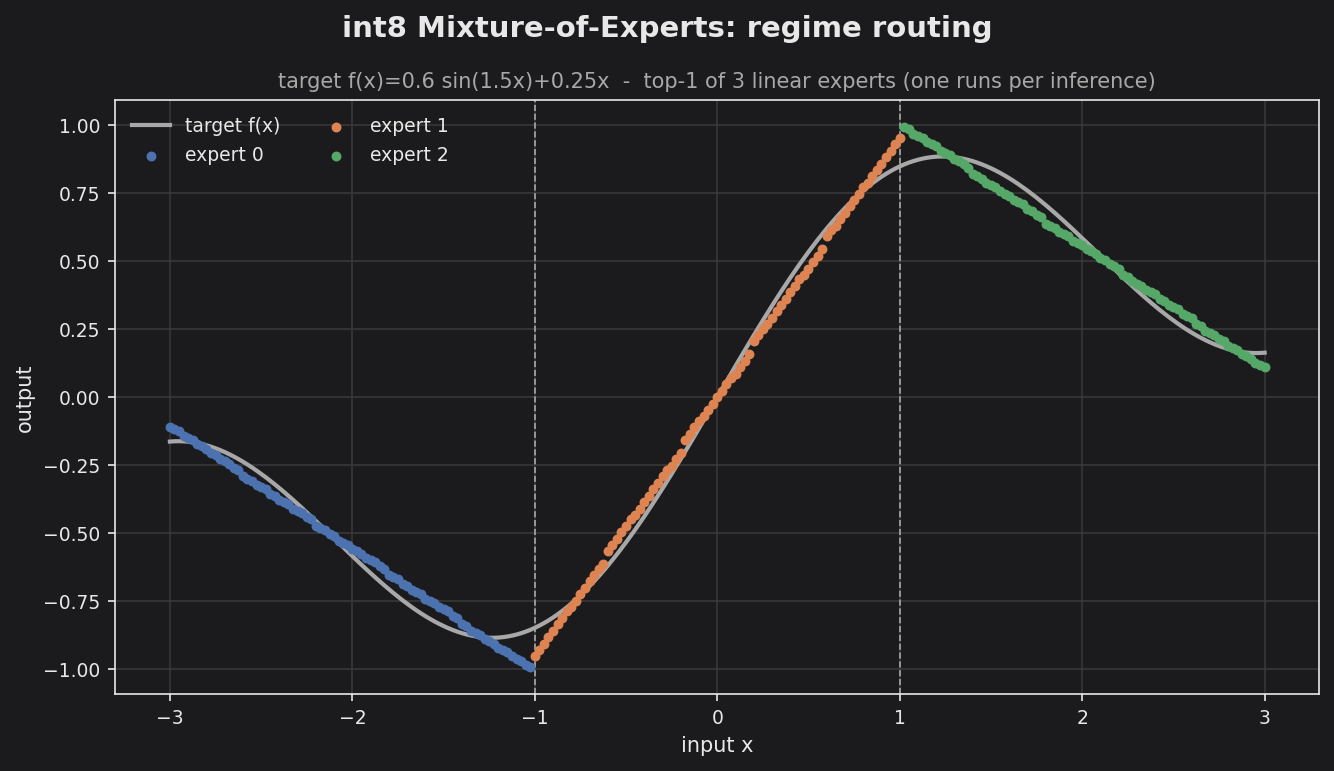
The color blocks are the routing map: each contiguous x-interval is the output of a single expert, the router’s argmax over three lines reduced to three regimes (boundaries dashed). The visible gap from the target curve is the three-line approximation, not int8 loss – one output LSB is ~0.008.