int8 MobileNetV2 Pipeline
A int8 MobileNetV2-shaped pipeline: two inverted-residual blocks (one stride-1 with a residual skip, one stride-2 without) wired around a stride-2 stem and a GAP + dense head. Demonstrates the inverted-residual unit and MobileNetV2’s linear-bottleneck rule on the int8 affine grid.
How it works
- Pipeline (NHWC,
16x16x4input):QPad2D→QConv2DPerChannel 3x3 s=2stem →qrelu, then IR block 1 (QPointwiseConv2D 8→32expand →qrelu→QDepthwiseConv2D 3x3 s=1→qrelu→QPointwiseConv2D 32→8project →QAddskip), then IR block 2 (expand → DW 3x3 s=2 → project 32→16, no skip), thenQGlobalAvgPool2D→QDense 16→4(int8 logits). - Linear bottlenecks: the 1x1 projection convolutions are deliberately not followed by
qrelu, matching MobileNetV2’s design rule (expand → DW → project keeps high-rank features in the expanded space and projects back without a nonlinearity).QDepthwiseConv2Dis per-channel weight-scaled (TFLite mandate);qreluandQGlobalAvgPool2Dare pass-throughs that reuse the upstream(scale, zero_point). - Every layer is pure integer at runtime with int32 accumulators; calibration (
FLOAT=1 STD=1) is host-only.make runpasses within 50% of logits range.
Build and run
cd examples/mobilenetv2_int8
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
Built with -DTINYMIND_ENABLE_QUANTIZATION=1. Extra targets:
make bench— CSV cycle/byte report tooutput/mobilenetv2_int8.csvmake golden— int8 logits for the 4-sample test set tooutput/mobilenetv2_int8.golden(consumed byunit_test/integration, locked byte-for-byte across SIMD gate combos)
Output
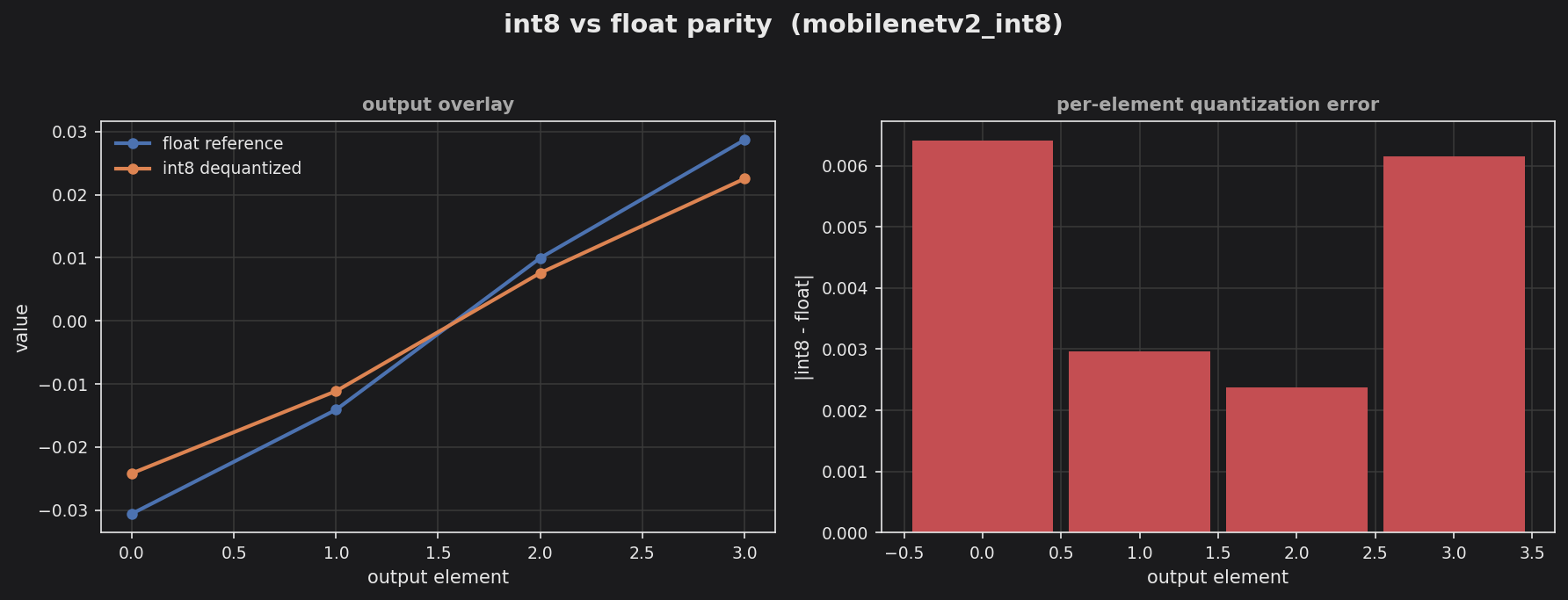
Left panel overlays the float reference against the int8-dequantized logits across the 4 output classes — the two tracks track the same monotone trend with a small gap at the extremes. Right panel shows the per-element absolute error staying under ~0.007, comfortably inside the 50% pass threshold for this two-inverted-residual-block pipeline.