KWS Cortex-M (int8 pipeline)
The same keyword-spotting pipeline as the float runner, with every layer replaced by its quantized cpp/q*.hpp counterpart. Demonstrates an end-to-end post-training int8 path: int8 weights and activations, int32 accumulators, and an integer Requantizer between layers — no float arithmetic on the inference path.
How it works
- Pipeline:
QConv2D 3x3 (8 filters)→QMaxPool2D 2x2→QDepthwiseConv2D 3x3 (per-channel)→QPointwiseConv2D 8→16→QGlobalAvgPool2D→QPointwiseConv2D (dense) 16→10, all int8 over a20x20x1int8 input. - Each layer rescales between stages with a Q0.31
(multiplier, shift)Requantizer;QDepthwiseConv2Dcarries a per-channel Requantizer array (TFLite mandate), the other layers use a single per-tensor Requantizer. - Host-side calibration via
cpp/include/qcalibration.hpp—quantizeBuffer(symmetric int8 weights),computePerChannelSymmetricScales(depthwise per-channel scales),buildRequantizer(fold input/weight/output scales into the integer pair). The deployable shape isQUANT=1 FLOAT=0 STD=0(no<cmath>); this host runner keepsFLOAT=1 STD=1so it can calibrate.
Build and run
cd examples/kws_cortex_m_int8
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
Built with -DTINYMIND_ENABLE_QUANTIZATION=1. make csv extracts the per-layer CSV block to output/kws_cortex_m_int8.csv; make plot renders it. Compare the totals at the bottom of this runner’s summary against the float runner — int8 weights occupy one byte versus four, so the convolutional weight footprint is roughly 4x smaller.
Output
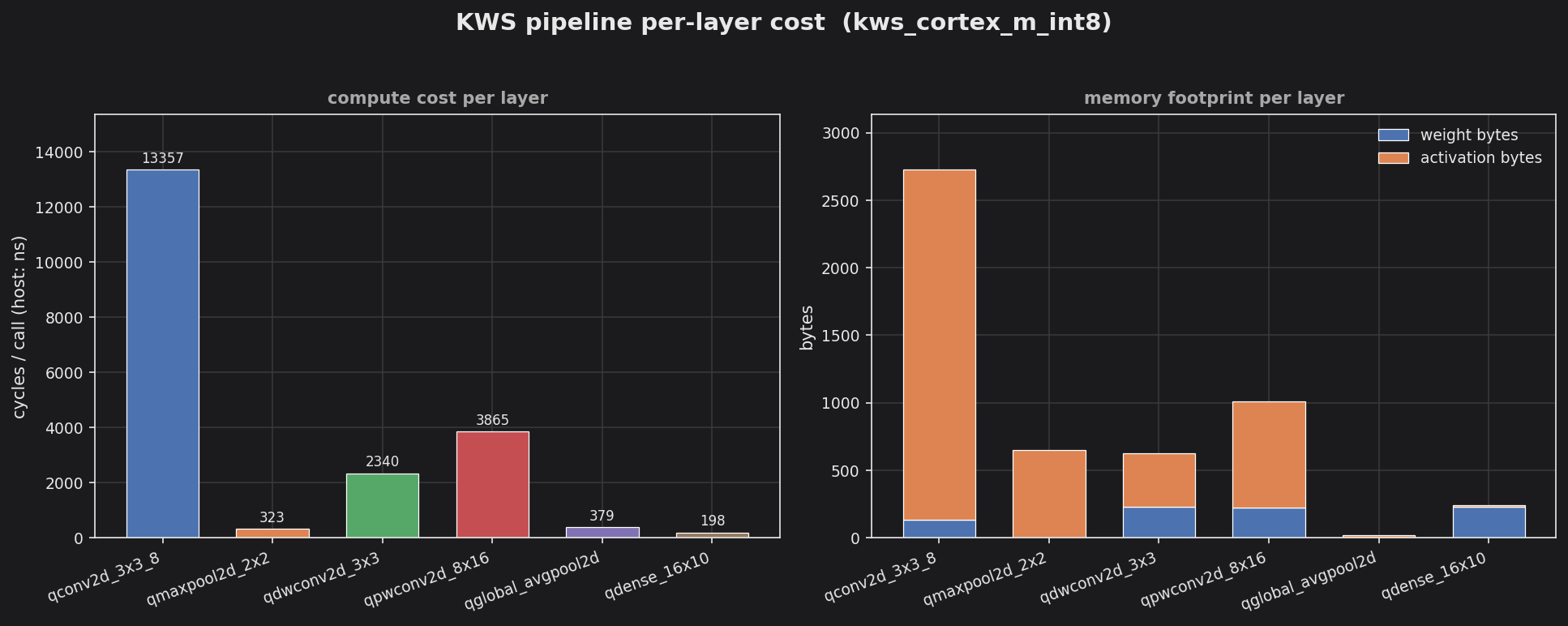
Left panel: per-call compute cost (host nanoseconds), with the leading QConv2D dominating as in the float pipeline. Right panel: the per-layer footprint split into weight bytes (blue) and activation bytes (orange) — the y-axis tops out near 3000 bytes versus 12000 for the float runner, the headline win of storing activations and weights as int8.