int8 Transformer Encoder Stack
The single-block encoder grown into an end-to-end model that starts from token ids: an int8 embedding gather, fixed sinusoidal positional encoding, and a stack of encoder blocks — every stage pure integer.
How it works
- Pipeline (
Vocab=16, S=8, E=8, F=16, NUM_BLOCKS=2):QEmbedding→QPositionalEncoding1D→EncoderBlock × N, where each block isQLayerNorm1D→QAttention1D(linear, ReLU-kernel) →QAddskip →QLayerNorm1D→QDense E→F→qrelu→QDense F→E→QAddskip. QEmbedding(cpp/qembedding.hpp) gathers int8 rows from a[Vocab, E]table by token id. Anullptrrequantizer means the table already lives on the output activation grid (the common case — the embedding defines the grid the rest of the network calibrates to); a non-null requantizer rescales each gathered code onto a different downstream grid.QPositionalEncoding1D(cpp/qpositional.hpp) injects token order by adding a per-position table to the embedding sequence. It is a thin wrapper overQAdd, binding the constant table as the second operand. The host-onlysinusoidalPositionalTable()helper generates the fixed “Attention Is All You Need” encoding; a learned table imported from a trained model drops in unchanged.- Blocks are grid-chained: block N’s output affine grid feeds block N+1’s input grid directly, exactly as a real deployment stacks layers. Calibration is host-side over an 8-sample synthetic token dataset.
- End-to-end error is ~1% of output range (pass threshold 40%) for the full embedding + positional + 2-block stack, with no QAT and no cross-layer equalization.
Build and run
cd examples/transformer_encoder_stack_int8
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
Built with -DTINYMIND_ENABLE_QUANTIZATION=1 (plus FLOAT=1 STD=1 for host calibration). Extra target:
make golden— int8 byte stream for the bundled test set tooutput/transformer_encoder_stack_int8.golden
For standard (softmax) self-attention instead of the linear kernel, see the softmax-attention variant.
Output
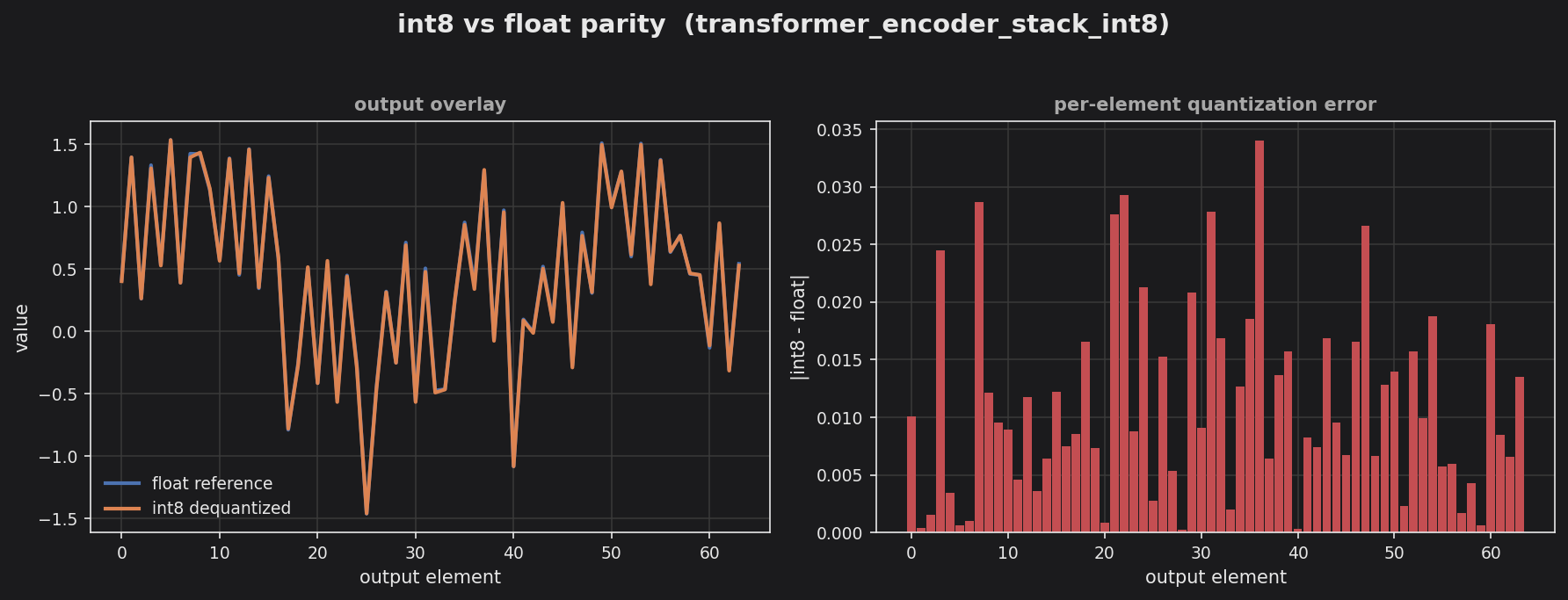
Left panel overlays the float reference against the int8-dequantized output across all 64 elements — the two tracks are nearly indistinguishable. Right panel shows the per-element absolute error, all under ~0.034, consistent with the ~1% of output range for this embedding + positional + 2-block int8 stack.