Elman Network — Japanese Vowels Speaker Recognition
The full embedded deployment story for a recurrent network: train offline in floating point, deploy in the smallest fixed-point format that holds the accuracy.
How it works
- Dataset: Japanese Vowels (UCI ML Repository, id 128). Nine male speakers utter the Japanese vowel /ae/; every utterance is 7–29 frames of 12 LPC cepstrum coefficients. 270 train / 370 test utterances; task is identifying the speaker from the sequence.
- The task is genuinely temporal — a single frame is ambiguous between speakers; the trajectory across the utterance discriminates. An
ElmanNeuralNetworkwalks the frames one at a time, carrying context in its recurrent hidden layer; per-frame class scores are summed over the utterance and the speaker is argmax. - An
ElmanNeuralNetwork<double, 12, 16, 9>is trained offline on the host (per-frame backprop against the one-hot speaker target, recurrent context zeroed at every utterance boundary). The trained weights — input, recurrent, output, biases — are then copied into inference-only (IsTrainable = false) fixed-point networks at Q16.16, Q8.8, and Q4.4, saturating each weight to the target format’s range. - Inputs are per-feature z-scored (train statistics) then divided by 3, so they land in roughly [-1, 1] — representable even at Q4.4 resolution.
Results
| Format | Weight storage | Test accuracy |
|---|---|---|
| float64 | 4936 B | 94.05% |
| Q16.16 | 2468 B | 94.32% |
| Q8.8 | 1234 B | 94.05% |
| Q4.4 | 617 B | 48.38% |
Q8.8 matches double-precision accuracy exactly with 4× smaller weights — the entire 617-weight network fits in 1.2 KB, no FPU required at inference. Q4.4 is below what this network needs: no weights clip, but the accumulated resolution loss through the recurrent loop collapses accuracy. The original paper’s baseline on this dataset is 94.1% (Kudo, Toyama & Shimbo, 1999) — the Q8.8 Elman network lands on it.
Build and run
cd examples/elman_vowels
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
make run trains offline and sweeps all four formats, writing output/vowels_accuracy.csv (one row per format), output/vowels_loss.csv (per-epoch training MSE), and output/vowels_confusion.csv (Q8.8 confusion matrix).
Output
Test accuracy (370 utterances, 9 speakers):
float64 accuracy 94.05% weights 4936 bytes
Q16.16 accuracy 94.32% weights 2468 bytes clipped 0/617
Q8.8 accuracy 94.05% weights 1234 bytes clipped 0/617
Q4.4 accuracy 48.38% weights 617 bytes clipped 0/617
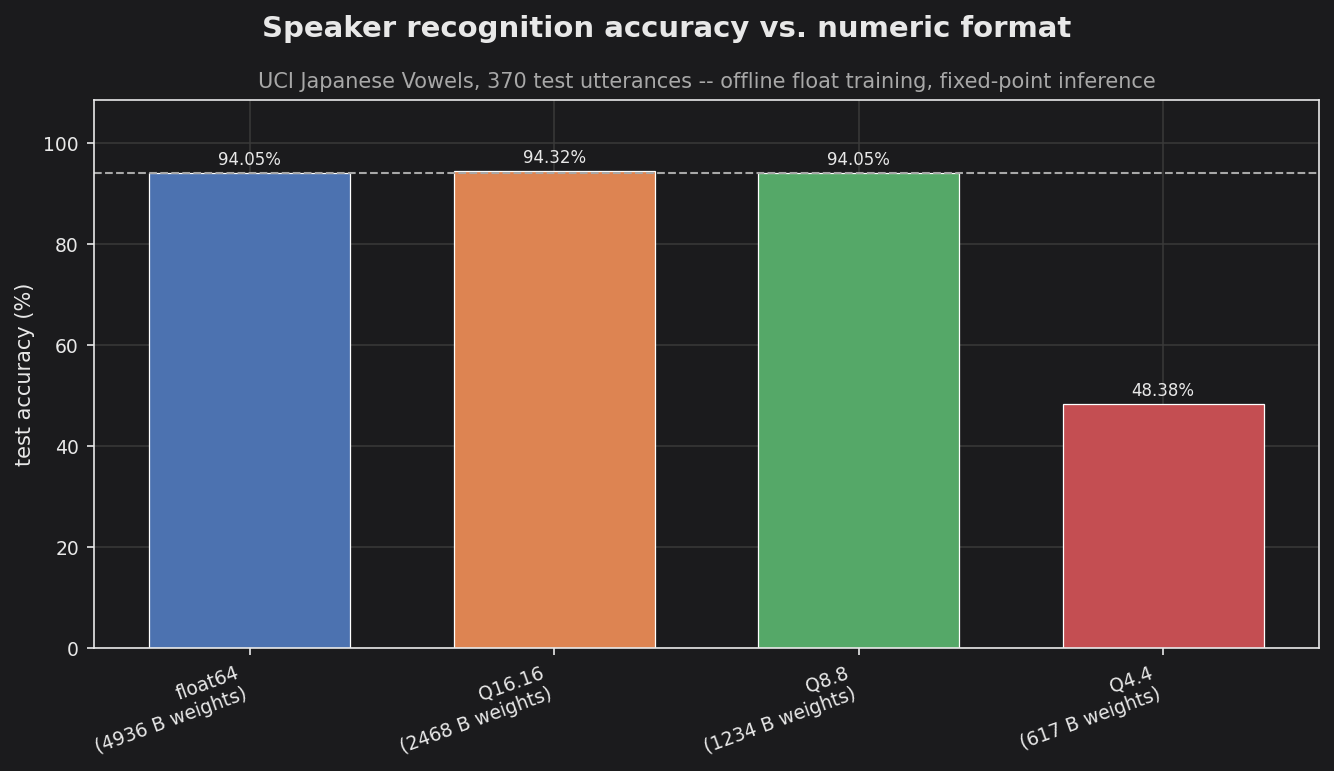
The float64 dashed reference line and the Q16.16/Q8.8 bars sit on top of each other; the Q4.4 bar collapses. The smallest deployable format for this network is Q8.8 — 16-bit weights, 16-bit activations, integer-only inference.