GRU XOR
Trains a Gated Recurrent Unit (GRU) network to learn XOR, exercising TinyMind’s recurrent network type on a small, well-understood task instead of a feed-forward MLP.
How it works
- Q16.16 signed fixed-point GRU network (
tinymind::GruNeuralNetwork) with two inputs, a single hidden layer of 8 GRU units, and one output; tanh hidden + sigmoid output, mean-squared-error loss, andGradientClipByValuefor recurrent stability. - XOR is not a sequential task — each
(x, y) -> zpair is independent — so the recurrent state is reset (resetState()) before every sample. Without the reset, state left over from the previous random pattern pollutes the prediction and the network never converges (it sticks near a constant 0.5 output). - The learning curve is the deterministic 4-case XOR error (state reset before each case), sampled through training — a clean convergence signal rather than the noisy per-sample error. Learning rate / momentum (0.5 / 0.9) are tuned for this small recurrent task and overridable on the command line.
Build and run
cd examples/gru_xor
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
make run writes output/gru_xor_results.csv (iteration, xor_error) and the decision-surface CSV output/gru_xor_decision_surface.csv (a 41×41 sweep of the trained GRU over the input grid), and prints a per-pattern report. You can override the optimizer with ./output/gru_xor <learningRate> <momentum>.
Output
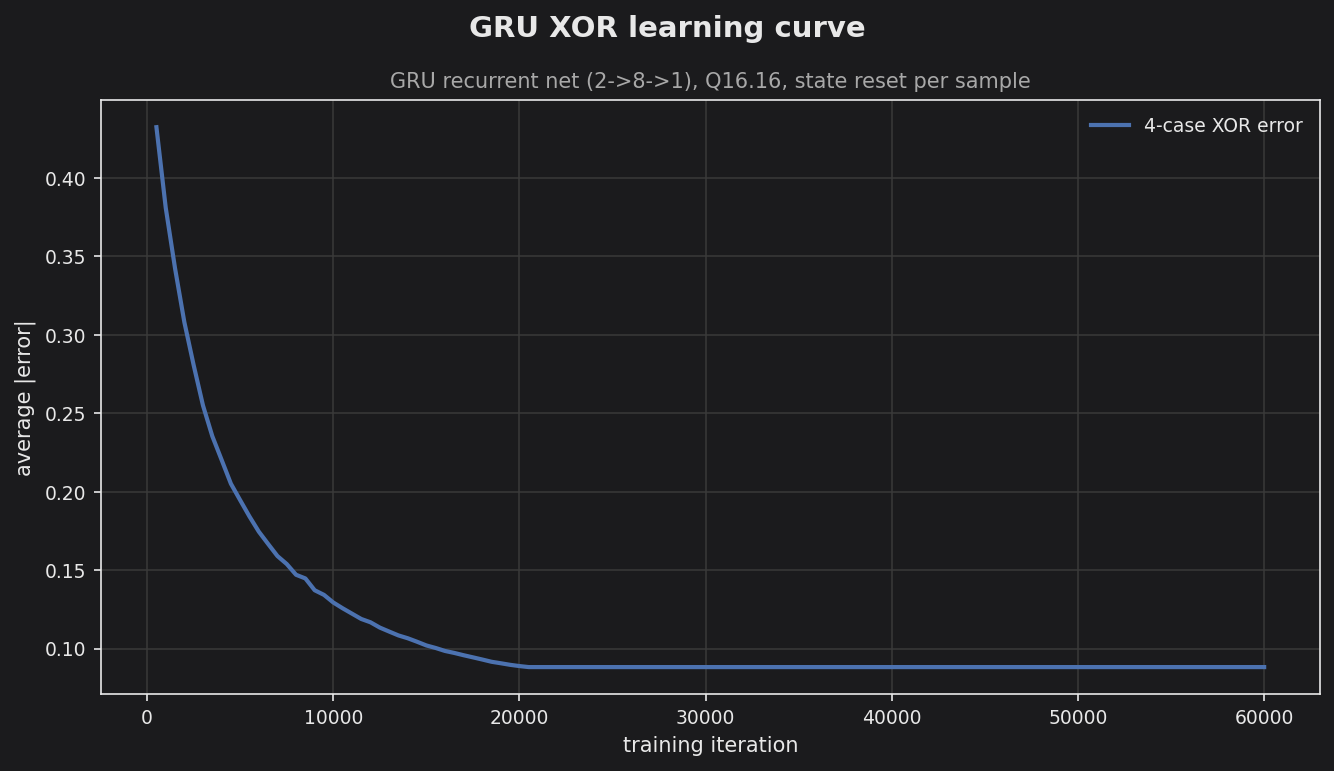
The 4-case XOR error falls smoothly from ~0.5 (chance) to ~0.09 and plateaus. All four patterns are classified correctly with clear margins (predictions ≈ 0.09 / 0.91); the residual ~0.09 is just the sigmoid output not fully saturating to 0/1 at this network size and fixed-point precision.
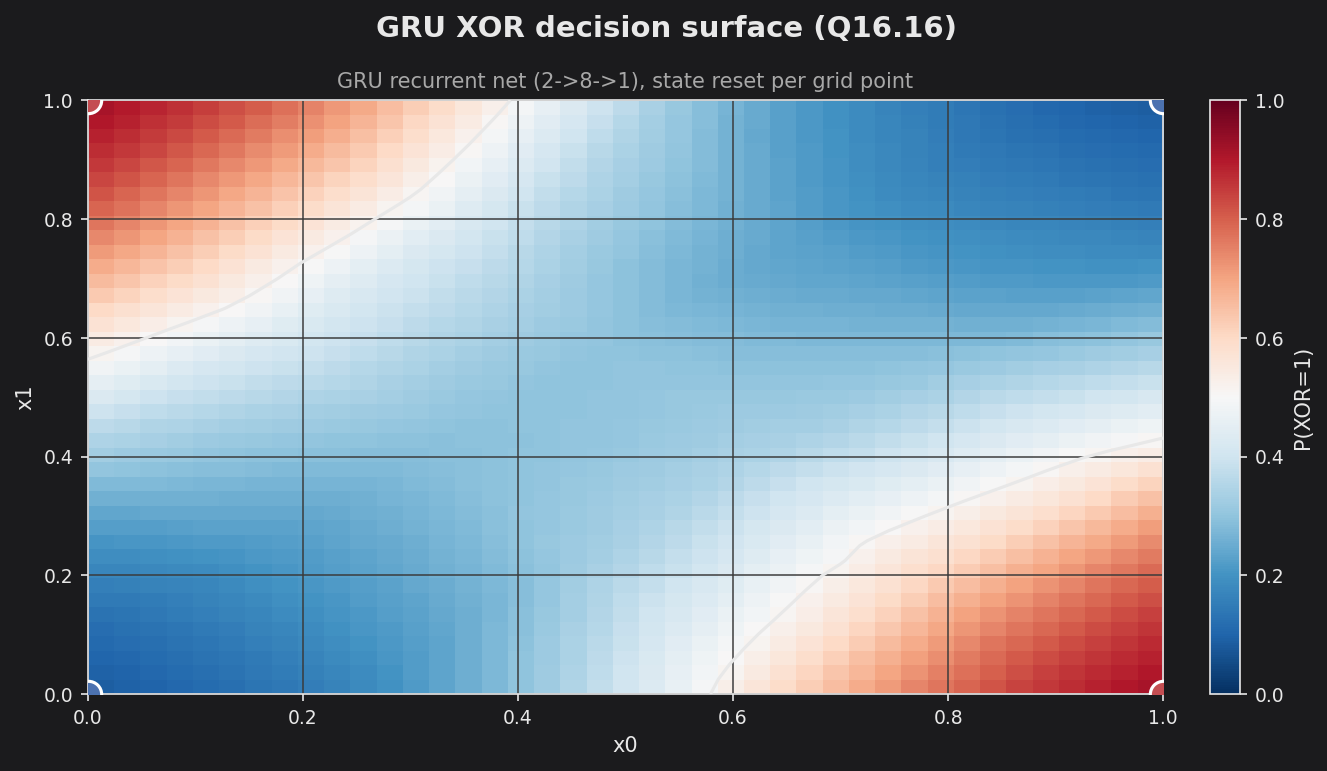
Sweeping the trained GRU over the [0,1]² input grid — resetting the recurrent state at each point — gives the predicted-vs-actual view: the heatmap is P(XOR=1), the line is the 0.5 boundary, and the four corner markers are the ground-truth targets (red = 1, blue = 0). The surface is the clean XOR saddle, with each corner firmly inside the matching region — the same presentation as the fixed-point and PyTorch XOR examples.