int8 ResNet-18 Stem + Block
A int8 ResNet-18-shaped stem plus one basic-block stage, exercised end-to-end on a deterministic synthetic dataset. Demonstrates that pooling, ReLU, and global-average-pool are pass-throughs on the int8 affine grid, so consecutive layers reuse the upstream scale and zero_point instead of burning new requantizers.
How it works
- Pipeline (NHWC,
16x16x3input):QPad2D pad=3→QConv2DPerChannel 7x7 s=2→qrelu→QMaxPool2D 2x2 s=2→ basic block (QPad2D pad=1→QConv2DPerChannel 3x3→qrelu→QPad2D pad=1→QConv2DPerChannel 3x3→QAddskip →qrelu) →QGlobalAvgPool2D→QDense 8→4(int8 logits). QMaxPool2DandqreluBufferneither rescale nor shift the grid (max and clamp are pass-throughs), so the post-pool grid is the post-stem grid;QGlobalAvgPool2Dis an integer mean clamped to[qmin, qmax]that shares its input scale and zero_point with its output. Convs are per-channel weight-scaled with int32 accumulators.- Every layer is pure integer at runtime; calibration (
FLOAT=1 STD=1) is host-only. Weights are deterministic sinusoids (no PyTorch dependency);make runpasses within 40% of logits range.
Build and run
cd examples/resnet18_block_int8
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
Built with -DTINYMIND_ENABLE_QUANTIZATION=1. Extra targets:
make bench— CSV cycle/byte report tooutput/resnet18_block_int8.csvmake golden— int8 logits for the 4-sample test set tooutput/resnet18_block_int8.golden(consumed byunit_test/integration, locked byte-for-byte across SIMD gate combos)
Output
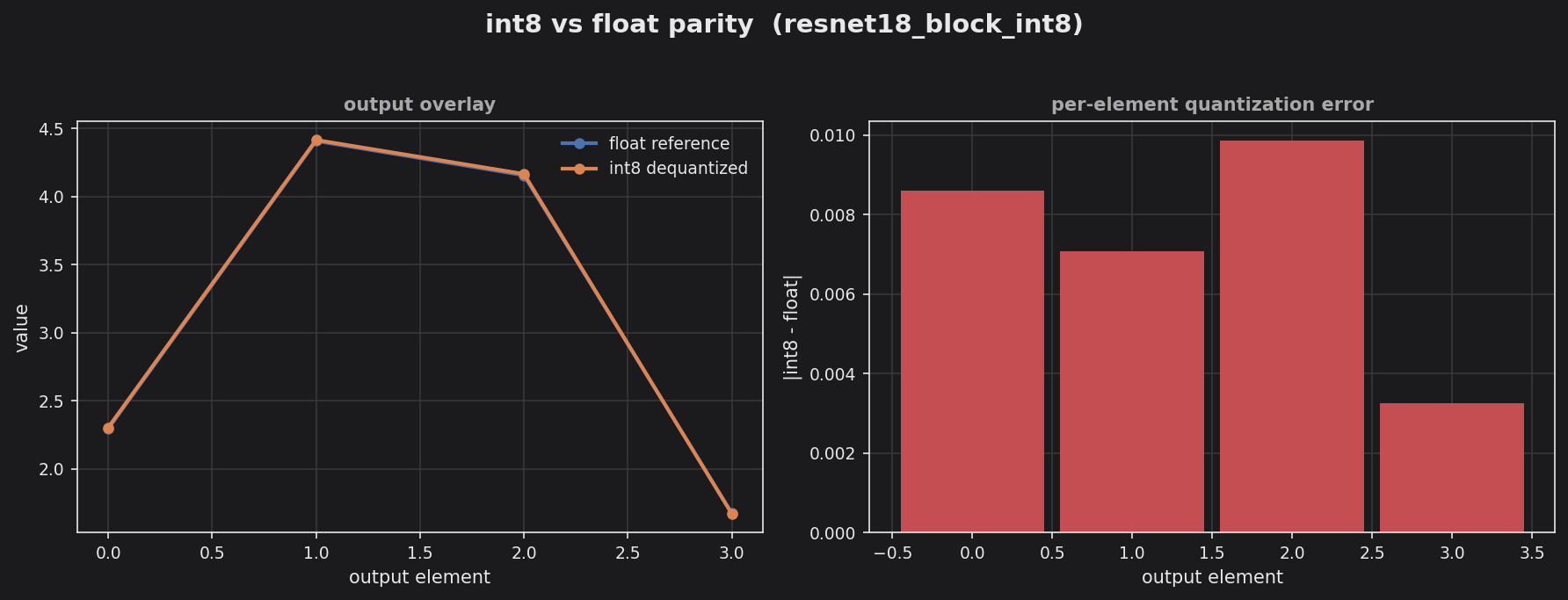
Left panel overlays the float reference and int8-dequantized logits across the 4 output classes — the two tracks sit on top of each other. Right panel shows the per-element absolute error, which stays under 0.01, far inside the 40% pass threshold despite the deep stem-plus-block chain.