int8 Transformer Encoder Block
A single int8 transformer encoder block built from the Phase 11 normalization, Phase 10 composition, and Phase 13 attention primitives. Demonstrates int8 LayerNorm, linear (ReLU-kernel) self-attention, residual adds, and a feed-forward sublayer running end-to-end as pure integer.
How it works
- Pipeline (
S=4, E=8):QLayerNorm1D→QAttention1D(linear, ReLU-kernel) →QAddskip →QLayerNorm1D→QDense E→16→qrelu→QDense 16→E→QAddskip. QAttention1Dis the linear-attention primitive (ReLU kernel feature map instead of softmax, O(N·D·P + N·P²)). ReLU on the Q’/K’ projections and on the FFN’s post-Dense1 activations is folded into the upstream Requantizer by raisingqminto the destination zero_point — the same fused-clamp pattern used across the Q* family. Drop-inQAttentionSoftmax1D/QMultiHeadLinearAttention1Dcover softmax and multi-head variants.- Calibration is host-side: the block runs in float over an 8-sample synthetic dataset to collect every intermediate tensor’s range, then fits per-tensor activation params (
computeAffineParamsAsymmetric) and per-tensor symmetric weight scales. Block end-to-end error is ~2% of output range (pass threshold 40%) — a six-stage int8 chain (LN, Attn, Add, LN, FFN, Add) with no QAT.
Build and run
cd examples/transformer_encoder_int8
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
Built with -DTINYMIND_ENABLE_QUANTIZATION=1 (plus FLOAT=1 STD=1 for host calibration). Extra target:
make golden— int8 byte stream for the bundled test set tooutput/transformer_encoder_int8.golden(consumed byunit_test/integration)
Output
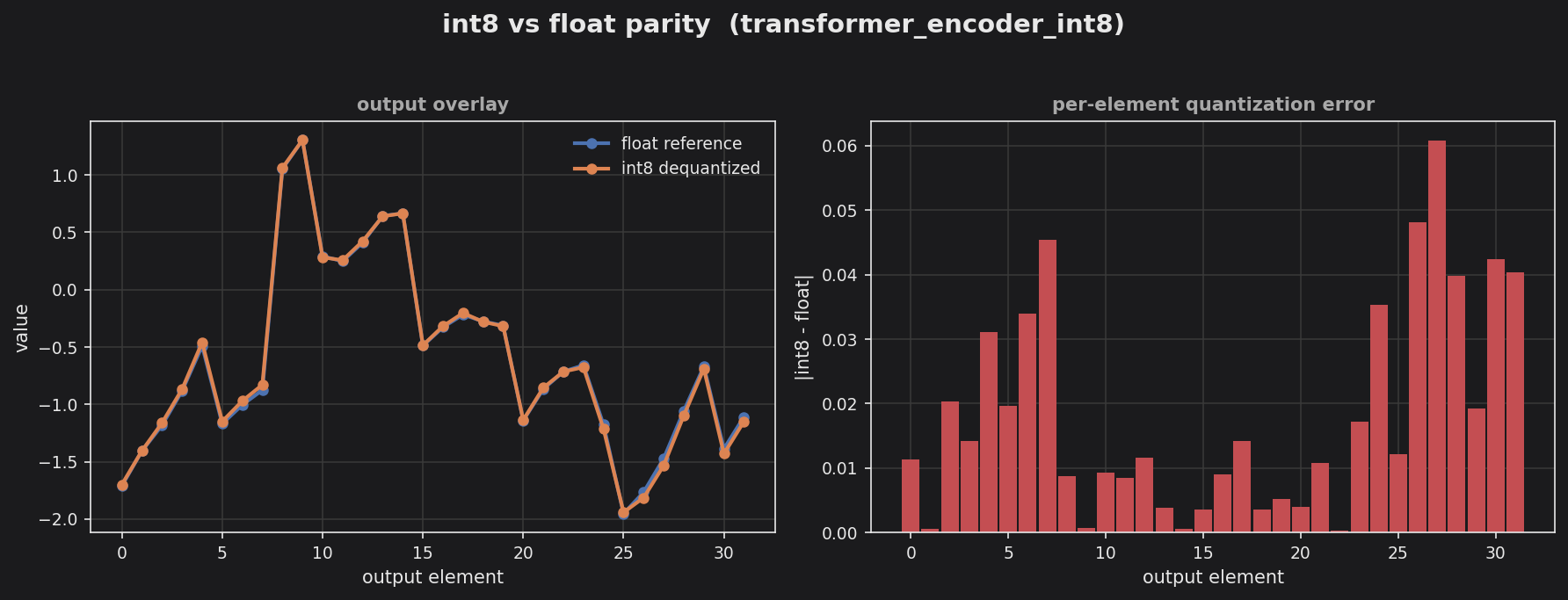
Left panel overlays the float reference against the int8-dequantized output across all 32 elements — the two tracks are nearly indistinguishable. Right panel shows the per-element absolute error, mostly under ~0.04, consistent with the documented ~2% of output range for this six-stage int8 encoder.