PyTorch → Q-format XOR
Trains an XOR MLP in PyTorch, exports its weights as Q16.16 fixed-point integers, and loads them into a TinyMind network for inference-only fixed-point evaluation — the Q-format counterpart to the int8 XOR demo.
How it works
- Pipeline: a 2-3-1 ReLU-hidden / Sigmoid-output MLP is trained in PyTorch (
xor.py), then each weight and bias is converted to a Q16.16 integer (raw value scaled by 2^16) and written one-per-line in the layer order the TinyMind file loader expects. - Demonstrates the existing single-
ValueTypeQ16.16 fixed-point path:xor.cpploads the exported weights into an untrainableMultilayerPerceptron<QValue<16,16>>viaNetworkPropertiesFileManager::loadNetworkWeightsand runs the same forward pass the trainer uses, plus a[0,1]²decision-surface sweep. This is the fixed-point sibling of the int8 affine XOR demo. - The imported fixed-point network reproduces the XOR decision boundary exactly — the four corners decode to ~0.007 / ~0.993, classifying all four cases correctly.
Build and run
cd examples/pytorch/xor
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
make run reads input/xor_weights_q16_16.txt and writes both the per-iteration trajectory (output/nn_fixed_xor.txt) and the decision-surface CSV. The weights file is produced by the PyTorch trainer/exporter: run python3 xor.py (requires torch + numpy + matplotlib in an isolated env), which trains the network and calls save_to_tinymind_format to emit the Q16.16 weight list. The Makefile compiles the Q16.16 sigmoid LUT (TINYMIND_USE_SIGMOID_16_16=1) and enables hosted IO for the file-based weight loader.
Output
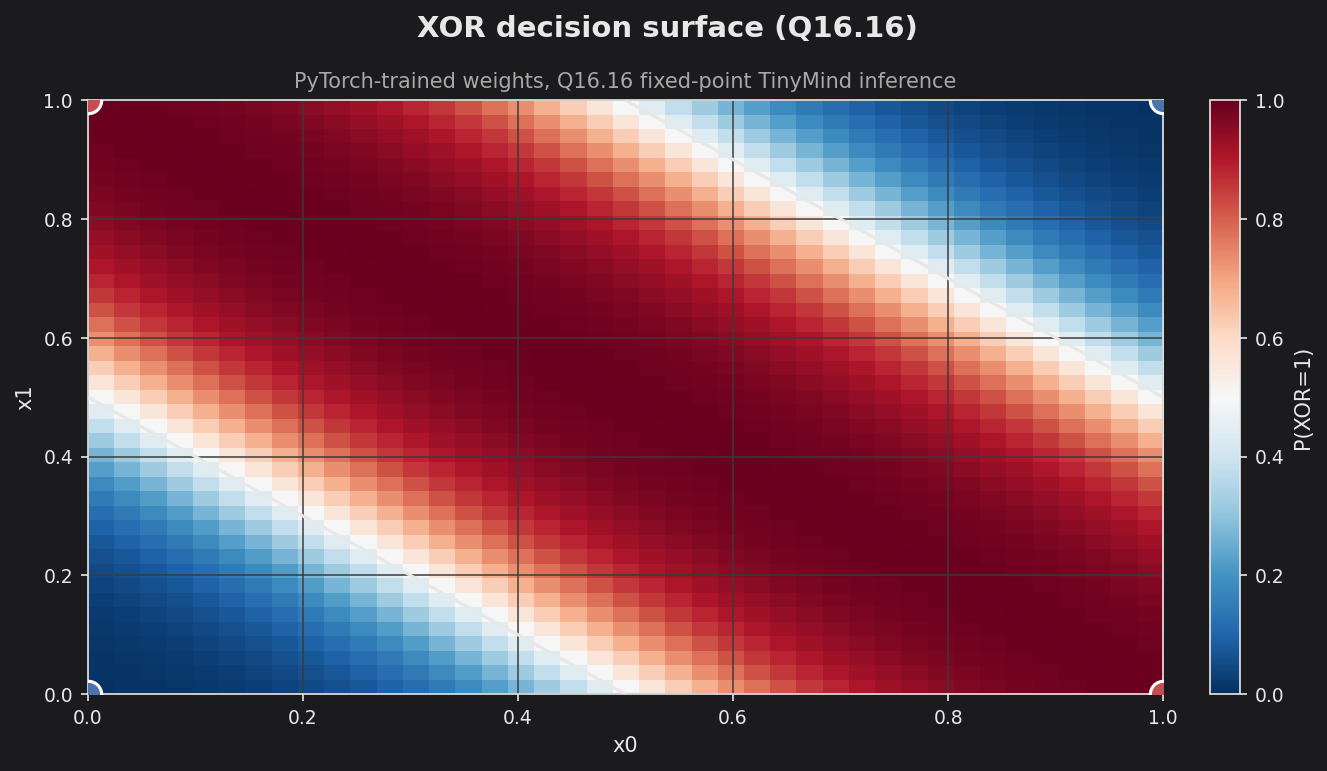
The heatmap sweeps the fixed-point network over the [0,1]² input grid. The off-diagonal corners (0,1) and (1,0) saturate deep red (P(XOR=1) → 1) and the matching corners (0,0) and (1,1) deep blue (→ 0), with the white 0.5 contour marking the learned boundary — the Q16.16 inference path recovers the same XOR surface as the float-trained reference.