Mixed-Precision KWS (int8 + fp16)
A keyword-spotting-shaped pipeline that brackets an fp16 attention head between an int8 feature frontend and an int8 classifier, exercising the Phase 9 qbridge converters and the software half-precision storage tier in production shape.
How it works
- Pipeline:
QDenseint8 frontend →qrelu→affineI8ToFp16Bufferbridge → fp16 linear (ReLU-kernel) self-attention with a residual skip and mean-pool over the sequence →fp16ToAffineI8Bufferbridge →QDenseint8 classifier. Frontend/classifier MACs accumulate in int32; the attention head computes in float promoted fromfp16_tstorage. - Demonstrates the Phase 9 mixed-precision qbridge converters (
affineI8ToFp16/fp16ToAffineI8) plus the softwarefp16_tstorage tier — the bridges run scalar at the layer boundary as pointwise converters, never inner-loop primitives, so the same helpers also serve a Q-format / int8 / Q-format chain. - The int8 logits track the end-to-end float reference closely; per-element quantization error stays on the order of 1e-3 of the output range on the bundled 4-sample synthetic test set.
Build and run
cd examples/mixed_precision_kws
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
TINYMIND_ENABLE_FP16=1 is required (already set in the bundled Makefile, alongside TINYMIND_ENABLE_FLOAT=1, STD=1, and QUANTIZATION=1); with the FP16 gate off the build fails at the bridge call sites. make bench writes a CSV cycle/byte report and make golden emits the int8 logit byte stream for the test set.
Output
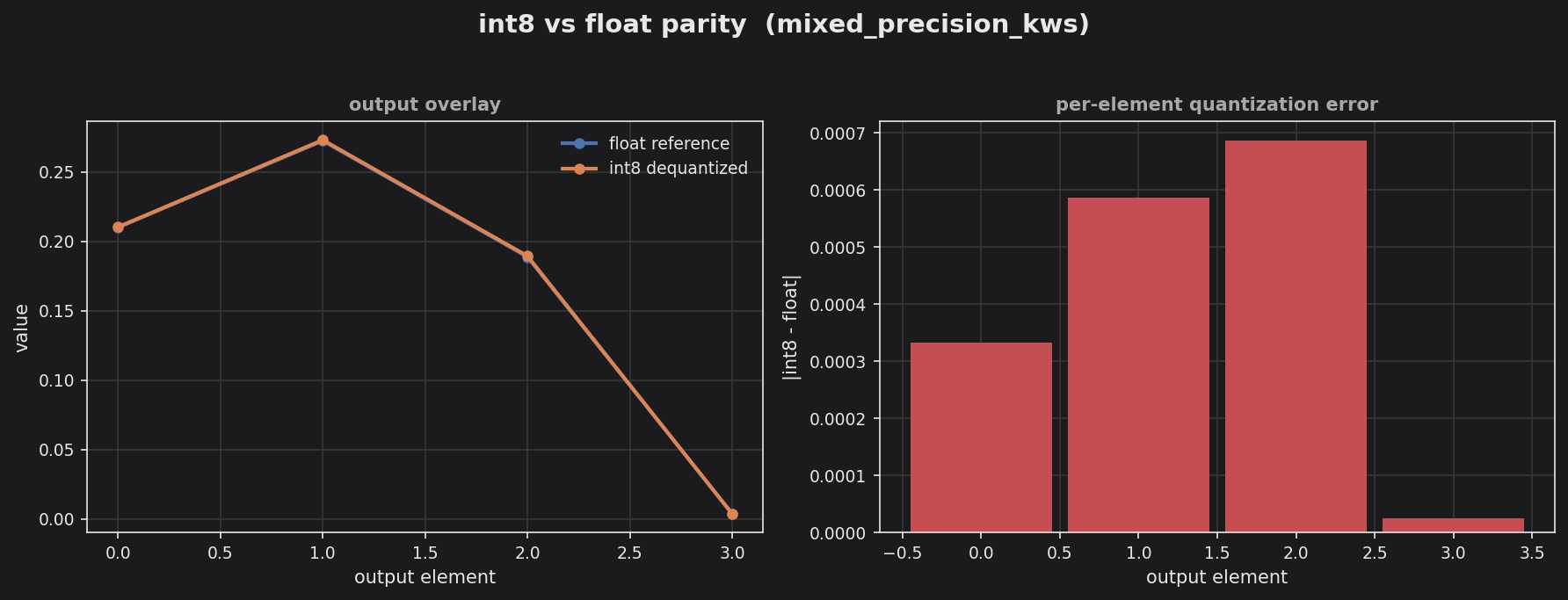
The left panel overlays the int8-dequantized output on the float reference across the four classifier outputs — the two curves are visually indistinguishable. The right panel shows the per-element absolute error, which peaks below 0.0007, confirming the int8-front / fp16-head / int8-classifier mix stays faithful to the all-float computation.