SIMD Performance Matrix
A SIMD-gate benchmark that builds the same int8 QConv2D 3x3 + QDense block under several TINYMIND_ENABLE_SIMD_* gate combinations and emits one CSV row per backend. Demonstrates that every integer SIMD backend is bit-exact with the scalar reference while cycle counts vary by ISA.
How it works
- The same int8 MobileNetV2-shaped block (
QConv2D3x3 +QDense) is compiled once per backend; the default Makefile buildsscalar,avx2,avx512f, andavx512_vnni. Each binary emitsactive_backend, per-call timing, andconv_output_checksum/dense_output_checksum. - The checksum columns are identical across backends when Phase 14’s bit-exactness invariant holds (int8 × int8 products fit in int16, int32 accumulation is lane-order independent, the zero-point correction folds into a final scalar subtract). Any disagreement with the
scalarreference row is a backend bug — the checksum mixes a running sum with an FNV-style XOR-and-shift hash, so a one-byte error flips it visibly. - Backend dispatch is compile-time only (no
cpuid/ runtime detection): the build translates-march=flags into matchingTINYMIND_ENABLE_SIMD_*=1defines, and one ISA is selected per build.
Build and run
cd examples/perf_matrix
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
make (default) builds the scalar / avx2 / avx512f / avx512_vnni binaries; make release is the same -O3 build. The key target is make report, which runs every binary and writes the combined CSV to output/perf_report.csv (one row per backend); make run aliases make report. make plot renders the chart from that CSV. To bench an Arm gate, add a target with the matching cross-compiler and -march=...+dotprod plus the matching TINYMIND_ENABLE_SIMD_NEON* defines.
Output
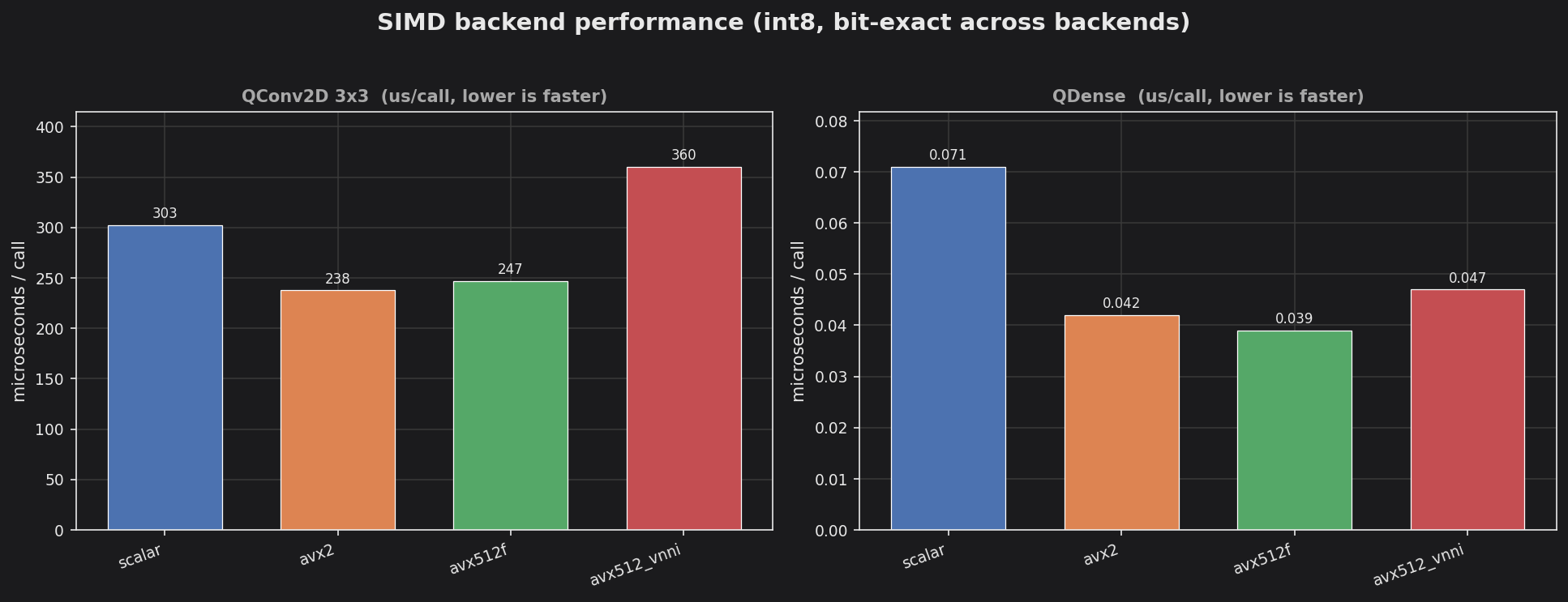
Two panels (the QConv2D and QDense stages differ by ~4 orders of magnitude in cost, so each gets its own y-scale). On this host AVX2 and AVX-512F are the fastest, beating scalar by roughly 20% on both stages; AVX-512-VNNI is slower here, a known AVX-512 frequency-throttling effect on this CPU. The headline is not the cycle delta but the invariant behind it — the output_checksum is identical across all four backends, so every speedup is bit-exact.