PyTorch Importer Demo
An end-to-end demonstration of the Phase 15 PyTorch → TinyMind int8 importer path: a small MLP is calibrated with three observers plus a Cross-Layer Equalization pass, then run as a pure-integer int8 forward and checked against the float reference.
How it works
- The host binary (
import_demo.cpp) carries a deterministic 3-8-4-2 ReLU MLP with hardcoded float weights, drives a 64-sample synthetic calibration set through the Phase 15 observers (RangeObserver,PercentileObserveron the hidden-2 activations,KLDivergenceObserveron the heavy-tailed logits), appliescrossLayerEqualizeDenseto rebalance fc1/fc2 channels pre-quantization, then runs both the float reference and the int8 forward. - Demonstrates the Phase 15 calibration and importer tooling: the three observer strategies feeding
computeAffineParams*, Cross-Layer Equalization (which is bit-equivalent to the original ReLU model — positive-homogeneous scaling commutes with ReLU), and theapps/import_pytorch/tinymind_importproduction flow that turns atorch.state_dictinto a realweights.hpp. - The int8 output matches the float reference to ~0.004 max-abs error on the bundled seed (tolerance 0.08); the binary engineers a 100:1 weight imbalance between fc1 and fc2 so CLE does real work, and the printed
CLE float driftline confirms the equalization is loss-free.
Build and run
cd examples/import_demo
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
make run prints the calibration ranges, the CLE drift, and the parity verdict (exit 0 on PASS). The C++ side needs no torch install. The production importer flow lives in demo.py — run it via make regenerate-pytorch (i.e. python demo.py), which trains the same-shape MLP in PyTorch, pulls numpy weights from torch.state_dict, and drives apps/import_pytorch/tinymind_import.import_pytorch_model to emit a weights.hpp (requires torch + numpy in an isolated env).
Output
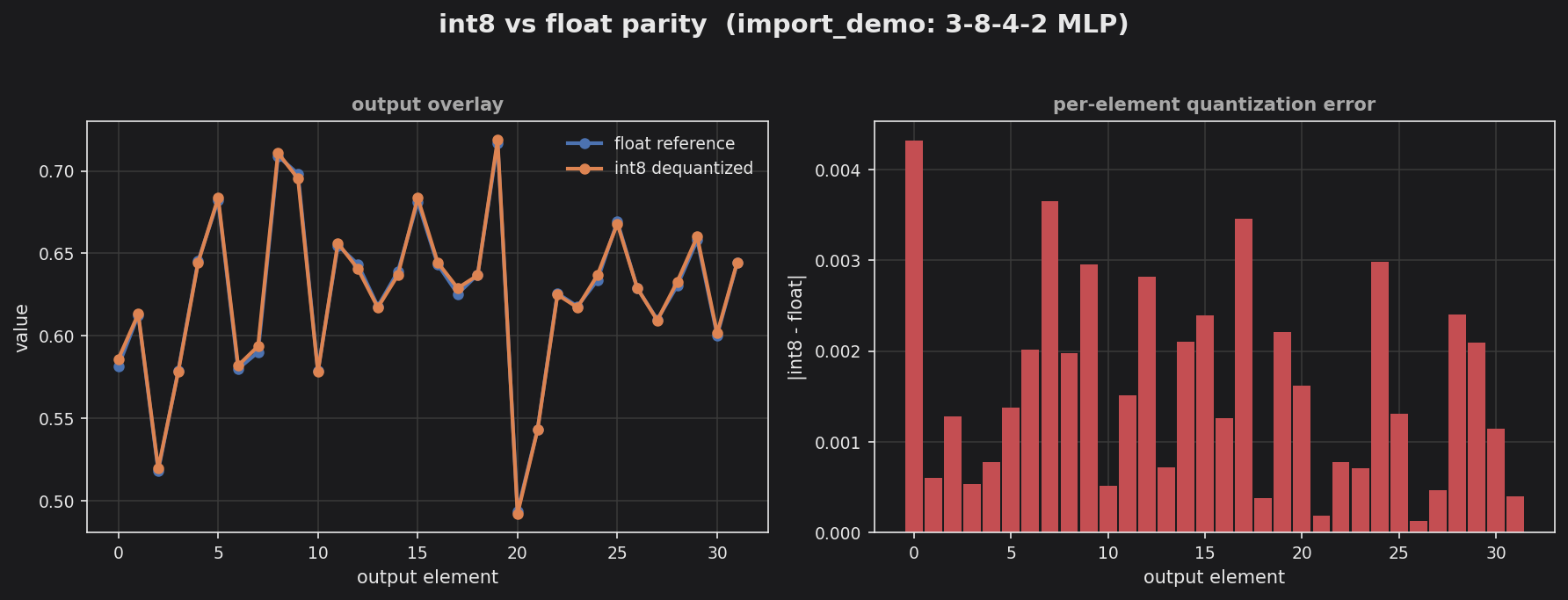
The left panel overlays the int8-dequantized output on the float reference across the 32-element flattened test output — the two curves overlap almost everywhere. The right panel’s per-element error tops out near 0.0043, showing the full observer + CLE + int8-quantization pipeline reproduces the float model to within a few thousandths.