Q-Learning Maze
Learns the shortest path out of a small six-room maze using tabular Q-learning. The agent starts in a random room and explores until it reaches the exit, updating a Q-table from each experience.
How it works
- Classic tabular Q-learning (
tinymind::QLearnerwith aQTableRewardPolicy) over six states (rooms 0-5, where 5 is outside the maze) and six actions; no neural network involved. - Demonstrates the reinforcement-learning core: an environment with a reward table, epsilon-style random exploration controlled by a
RandomActionDecisionPoint, and Q-value updates from(state, action, reward, newState)experiences. - Exploration is annealed late in training (the random-action probability is scaled down after 400 of the 500 training episodes) so the agent shifts from exploring to exploiting the learned Q-table.
Build and run
cd examples/maze
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
make run writes two CSVs: output/maze_training.csv (500 training episodes) and output/maze_test.csv (100 greedy test episodes). The make plot target renders both via mazeplot.py; each CSV row is one episode’s state-by-step path.
Output
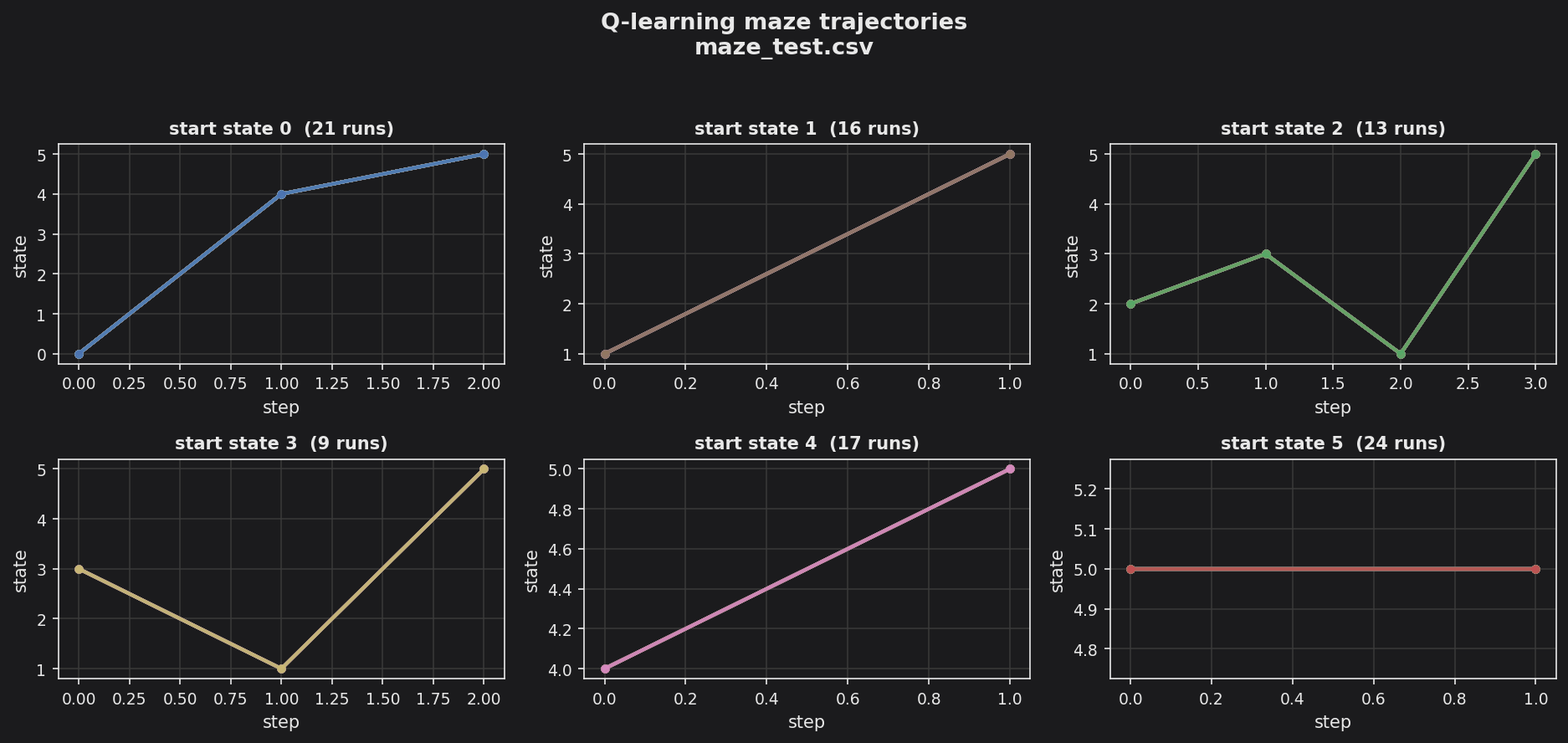
Each panel is one starting room and plots the greedy post-training trajectories (maze_test.csv). After the Q-table converges every run drives straight to the exit (state 5) in just a few steps from any start room — the paths overlap because the greedy policy is deterministic. (The exploratory maze_training.csv paths, also produced by make plot, are long and erratic by contrast.)