DQN Maze
Solves the same six-room maze as the tabular Q-learning example, but replaces the Q-table with a Deep Q-Network (DQN). The Q-values are approximated by a neural network trained from experience instead of stored explicitly.
How it works
- Deep Q-learning: a Q16.16 fixed-point multilayer perceptron (
tinymind::MultilayerPerceptronwrapped in aQValueNeuralNetworkPolicy) approximates the action-value function, with a periodically-synced target network for stable bootstrapping. - Demonstrates the function-approximation variant of reinforcement learning on the same environment as the tabular maze, so the two examples can be compared directly.
- Trains over 10,000 episodes (random exploration annealed over the final 1,000) with a per-episode step cap, then runs 100 greedy test episodes against the learned network.
Build and run
cd examples/dqn_maze
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
make run writes output/dqn_maze_training.csv (10,000 training episodes) and output/dqn_maze_test.csv (100 greedy test episodes); make plot renders both via dqn_mazeplot.py, one trajectory per episode grouped by starting room.
Output
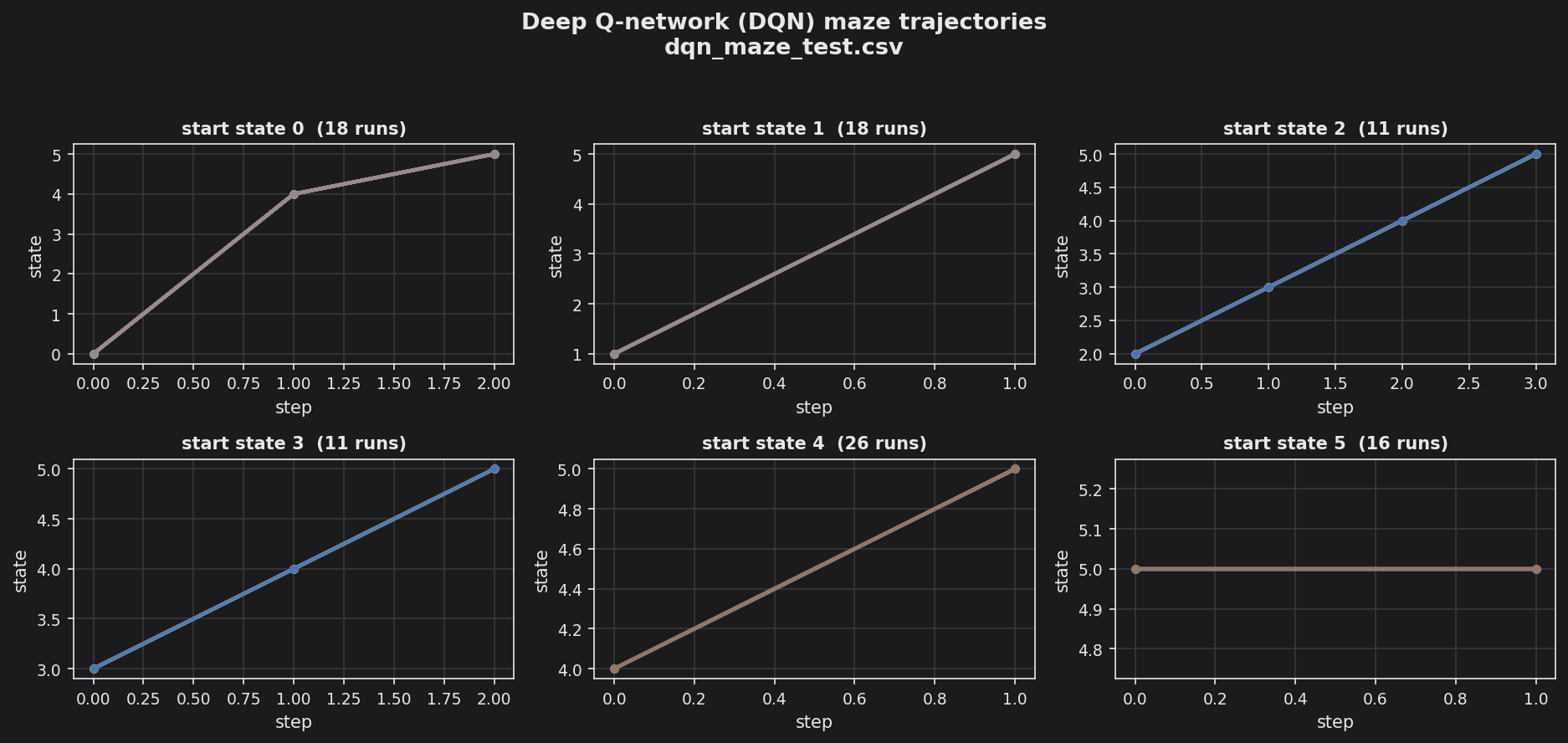
Each panel is one starting room and plots the greedy post-training rollouts (dqn_maze_test.csv). Once the value network is trained, every run drives straight to the exit (state 5) from any start room. Far more training episodes are needed than in the tabular case because the network learns the value function from scratch (the exploratory dqn_maze_training.csv paths are also produced by make plot).