int8 Transformer Encoder Stack (Softmax Attention)
The int8 encoder stack with standard (softmax) self-attention in place of the linear (ReLU-kernel) attention. Same embedding → positional → stacked-block pipeline; the difference is how each block computes attention weights.
How it works
- Pipeline (
Vocab=16, S=8, E=8, F=16, NUM_BLOCKS=2):QEmbedding→QPositionalEncoding1D→EncoderBlock × N, where each block isQLayerNorm1D→QAttentionSoftmax1D→QAddskip →QLayerNorm1D→QDense E→F→qrelu→QDense F→E→QAddskip. QAttentionSoftmax1Dfollows the TFLite int8 convention:- Project Q, K, V (no ReLU on the projections).
- Score = (Q · Kᵀ) / √P, requantized onto an int8 score grid. The 1/√P factor is folded into
score_requantizerat calibration time. - Per row: subtract the row max, look exp up in a 256-entry int32 LUT, normalize to the 1/256 probability grid at zero_point −128.
- Output = probabilities · V, requantized onto the block’s attention grid.
- The exp LUT (
buildQSoftmaxExpLUT) is the extra footprint this variant pays over the linear-attention stack — 1 KiB of int32 per distinct score grid, flash-resident on a freestanding target. The trade is true softmax weighting for an LUT plus a few more requantize stages. - End-to-end error is ~1% of output range (pass threshold 50% — looser than the linear stack’s 40% because softmax compounds more int8 stages: score grid, LUT, normalize). No QAT, no cross-layer equalization.
Build and run
cd examples/transformer_encoder_stack_softmax_int8
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
Built with -DTINYMIND_ENABLE_QUANTIZATION=1 (plus FLOAT=1 STD=1 for host calibration). Extra target:
make golden— int8 byte stream for the bundled test set tooutput/transformer_encoder_stack_softmax_int8.golden
Output
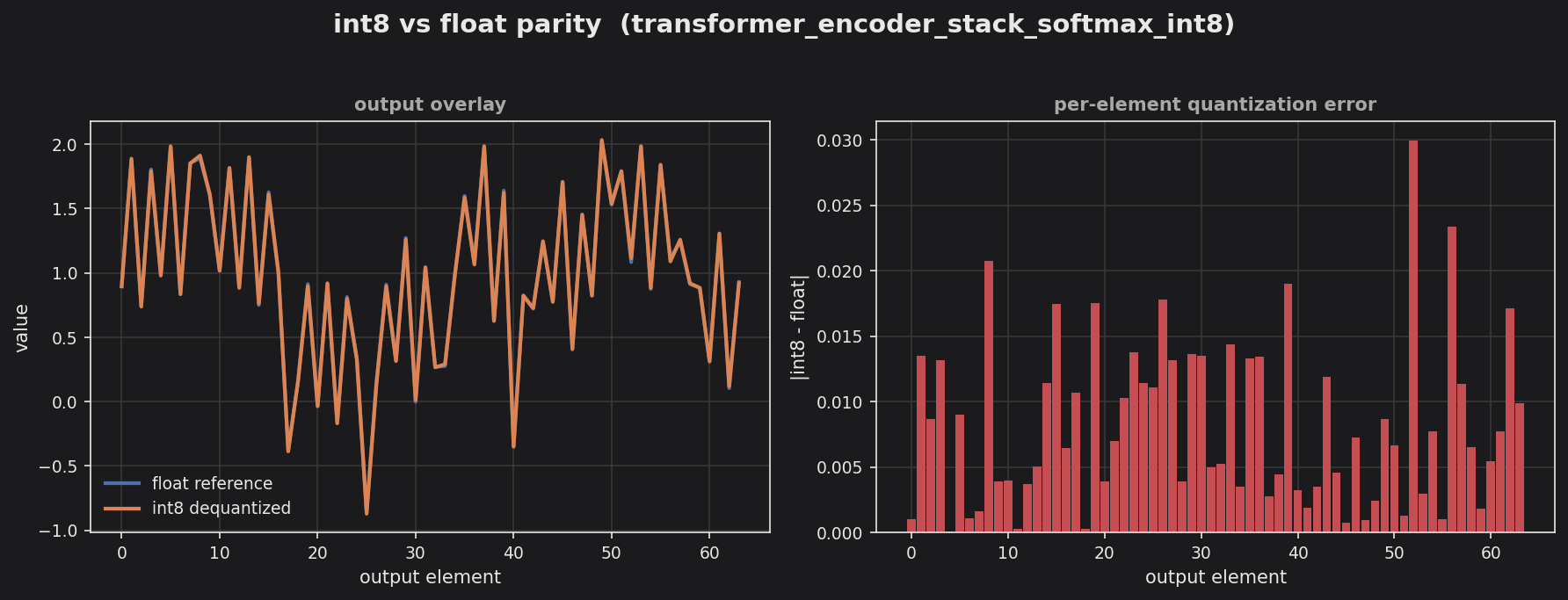
Left panel overlays the float reference against the int8-dequantized output across all 64 elements. Right panel shows the per-element absolute error, all under ~0.030 — on par with the linear-attention stack despite the additional softmax/LUT stages.