Int8 Affine Quantization
TinyMind ships a TFLite / CMSIS-NN style post-training int8 layer family that lives alongside the existing QValue Q-format pipeline and the float pipeline. Weights and activations are int8, accumulators are int32, and a per-layer integer Requantizer (Q0.31 multiplier + shift) rescales between layers without any floating-point math on the inference path.
This is a different kind of “quantization” than BinaryDense / TernaryDense. Those layers binarize / ternarize the weights themselves (1- or 2-bit storage, multiply-free MACs). The int8 path keeps a full integer multiply-accumulate but maps the float distribution onto an int8 grid via a calibrated (scale, zero_point) per tensor.
| Path | Storage | Multiply | Calibration | When it shines |
|---|---|---|---|---|
BinaryDense | 1-bit packed | XNOR + popcount | None (sign of latent weight) | Wide layers on ARMv7-M with popcount |
TernaryDense | 2-bit packed | conditional add/sub | Threshold percentile | Sparse layers, multiply-free |
| Int8 affine (this page) | int8 weights + int8 activations | int8*int8 -> int32 MAC | Per-tensor / per-channel scale + zero_point | Drop-in TFLite-shape deployment, MobileNet-style CNN |
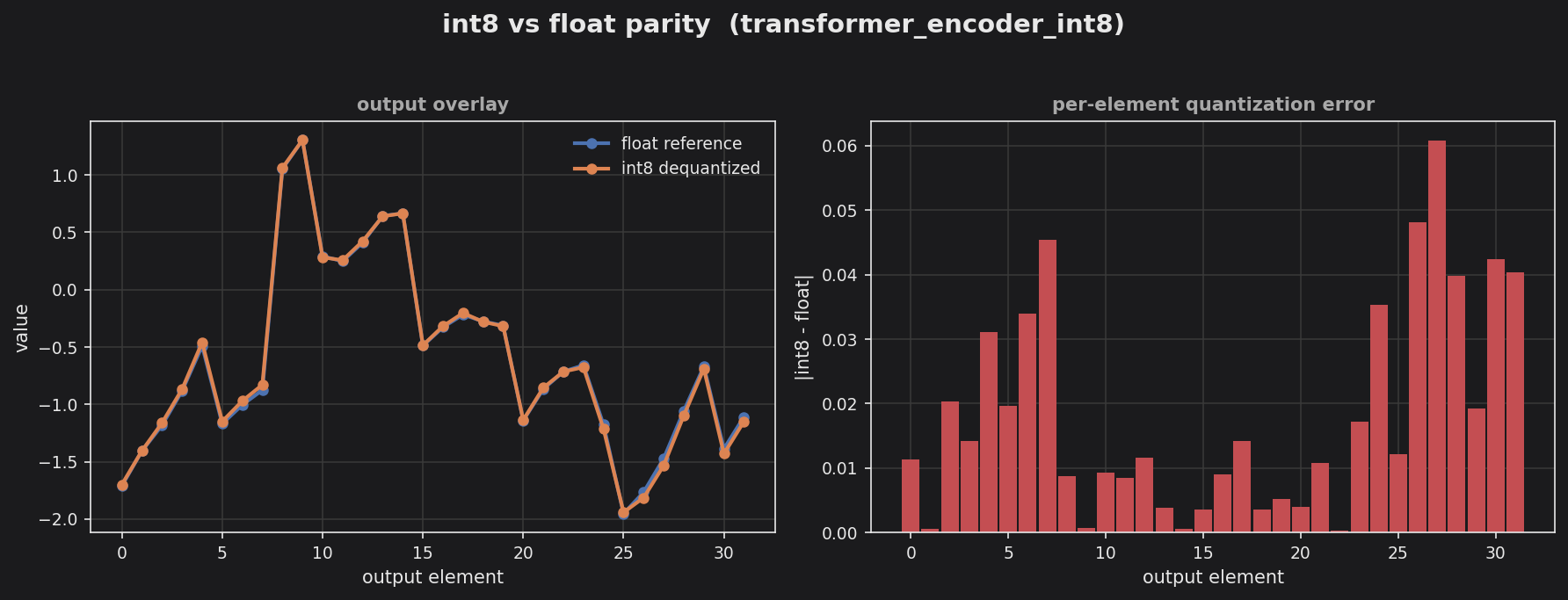
examples/transformer_encoder_int8: the pure-integer int8 block tracks the float reference closely; per-element quantization error stays small. More in the Example Gallery.
Q-format vs. Affine Quantization
Both are “fixed-point”, but they live in different layers of the abstraction stack:
QValueQ-format (existing TinyMind): a compile-time bit split.QValue<8, 8, true>is an int16 with a fixed binary point. There is no runtime scale, no zero_point, no per-tensor metadata — every value in the program shares the same grid. You pick the resolution once at the type level and the compiler propagates it.- Int8 affine quantization (this page): each tensor carries its own runtime
(scale, zero_point)pair fit from observed min/max during calibration.real = scale * (q - zero_point). Different tensors in the same model use different grids. The layer between them rescales with an integer(multiplier, shift)triple computed from the surrounding scales.
The two coexist; nothing in qformat.hpp or any single-ValueType layer changed when the int8 path was added.
Feature Gate
The whole int8 path is behind one preprocessor flag in cpp/include/tinymind_platform.hpp:
#define TINYMIND_ENABLE_QUANTIZATION 1
The deployable inference shape is TINYMIND_ENABLE_QUANTIZATION=1, TINYMIND_ENABLE_FLOAT=0, TINYMIND_ENABLE_STD=0 — int8 weights and activations, int32 accumulators, integer requantization, no <cmath>. Calibration helpers in cpp/include/qcalibration.hpp are additionally gated on FLOAT && STD so they only build host-side.
The unit_test/embedded regression matrix exercises this corner as the quant_freestanding build, alongside the four pre-existing (FLOAT, STD) corners.
Affine Model
real = scale * (q - zero_point)
scale is a positive float chosen during calibration; zero_point is the integer storage value that decodes back to 0.0. With int8 storage, q lives in [-128, 127] and zero_point is also clamped into that range so the float zero is always representable on the grid.
For weights TinyMind follows the TFLite convention: symmetric (zero_point = 0), qmax_signed = 127, -128 deliberately unused so a weight can be safely negated. For activations TinyMind uses asymmetric (scale, zero_point), with the observed range “nudged” to include zero before fitting.
Once a layer’s input scale s_in, weight scale s_w, and output scale s_out are fit, the integer requantization ratio is:
ratio = (s_in * s_w) / s_out
quantizeMultiplier(ratio, multiplier, shift) turns that float ratio into a Q0.31 multiplier and a shift exponent, both int32. At runtime, the layer multiplies its int32 accumulator by the multiplier with saturatingRoundingDoublingHighMul, applies roundingDivideByPOT, adds the destination zero_point, and saturates to [qmin, qmax]. Pure integer; the same code that ran on the host runs on a Cortex-M0 with no FPU.
Core Types
cpp/qaffine.hpp provides the runtime primitives:
template<typename StorageType_>
struct QAffineTensor
{
typedef StorageType_ StorageType;
#if TINYMIND_ENABLE_FLOAT
float scale; // host-only calibration metadata
#endif
StorageType zero_point;
};
template<typename SrcAccum_, typename DstStorage_>
struct Requantizer
{
int32_t multiplier;
int32_t shift;
DstStorageType zero_point;
DstStorageType qmin;
DstStorageType qmax;
DstStorageType apply(SrcAccumType acc) const;
};
Note that scale is compiled out under TINYMIND_ENABLE_FLOAT=0 — the freestanding inference binary holds only the integer zero_point plus the (multiplier, shift) from each layer’s Requantizer.
The two helpers saturatingRoundingDoublingHighMul and roundingDivideByPOT follow the gemmlowp / TFLite reference semantics bit-for-bit; tests in unit_test/quantization/ lock that down.
Layer Family
All layers are templated on <InputType, WeightType, AccumType, OutputType> (plus shape/size constants). Each carries its own Requantizer and accepts caller-owned weight / bias / lookup-table buffers — the same model can be built once on the host and re-used across many MCU targets.
Core layers
| Header | Layer | Notes |
|---|---|---|
qdense.hpp | QDense | Fully-connected; per-tensor weight scale |
qconv2d.hpp | QConv2D | NHWC, VALID padding, per-tensor weight scale |
qdepthwiseconv2d.hpp | QDepthwiseConv2D | Per-channel weight scale (TFLite mandates) |
qpointwiseconv2d.hpp | QPointwiseConv2D | 1x1 conv, per-tensor weight scale |
qpool2d.hpp | QMaxPool2D, QAvgPool2D, QGlobalAvgPool2D | Max needs no requantizer (input/output share scale); avg rounds the integer sum |
qactivations.hpp | qrelu, qrelu6, qApplyLUT | Pointwise + 256-entry int8 LUTs for sigmoid / tanh; clampForRelu folds the activation into the upstream Requantizer’s saturation pass |
Per-channel scales for QDepthwiseConv2D are mandatory in TFLite for accuracy reasons (the absolute weight magnitudes vary wildly across depthwise channels). The depthwise layer carries a Requantizer array of length NumChannels; everything else uses a single per-tensor Requantizer.
Per-channel siblings and composition ops
| Header | Layer | Notes |
|---|---|---|
qconv2d.hpp | QConv2DPerChannel | Same template signature as QConv2D but requantizers[NumFilters]. Use when ResNet/MobileNet-style accuracy demands per-channel weight scale on the standard conv. |
qpointwiseconv2d.hpp | QPointwiseConv2DPerChannel | Per-channel sibling of the 1x1 conv |
qadd.hpp | QAdd | TFLite ADD semantics — left_shift plus three (multiplier, shift) triples. Residual skips |
qmul.hpp | QMul | Single-Requantizer elementwise multiply |
qconcat.hpp | QConcat2_2D | Channel-axis concat with a per-input rescaler |
qpad.hpp | QPad2D | Constant pad. Padded cells get the input’s zero_point so they decode to true zero in the affine domain |
Normalization
| Header | Layer | Notes |
|---|---|---|
qbatchnorm.hpp | QBatchNorm1D, QBatchNorm2D | Per-channel (multiplier, shift, bias_addend) triple, built host-side from float gamma / beta / mean / variance. Standalone BN that cannot be folded. |
qlayernorm.hpp | QLayerNorm1D | Per-row integer mean / variance; 1/sqrt(var) via pure-integer Newton iteration (qInvSqrtQ30). Per-feature gamma (int16 Q1.14), per-feature beta (int32 in output scale) |
qsoftmax.hpp | QSoftmax1D | Two-pass int8 softmax: per-row max-subtract, 256-entry int32 exp LUT, int64 sum, TFLite output convention (scale 1/256, zp -128) |
foldBatchNorm (in qcalibration.hpp) is the matching host-side helper: fuse a Conv2D + BatchNorm pair into one fused Conv2D pre-quantization so the deployed graph never sees a BN layer.
Quantized recurrent cells
| Header | Layer | Notes |
|---|---|---|
qlstm.hpp | QLSTMCell | Four gates (i, f, g, o) in TFLite ordering. Each gate carries two rescalers into a shared LUT input scale, routes the pre-activation int32 through the sigmoid / tanh LUTs. Cell-state storage int8_t (deployable default) or int16_t (long unroll horizons, gate TINYMIND_ENABLE_INT16_ACCUM=1) |
qgru.hpp | QGRUCell | Three gates (r, z, n) in canonical ordering. Reset-before-multiply formulation. (1 - z) computed exactly in the sigmoid grid as -z |
qcfc.hpp | QCfCCell | Closed-form continuous-time (liquid) cell. Backbone trunk + two tanh heads + a sigmoid time-gate + the (1 - t) * ff1 + t * ff2 interpolation. Regular-sampling deployable form: the elapsed time ts is folded into the time-gate-A requantizer and the combined time bias at calibration. Reuses the QGRU (1 - t) == 128 - t sigmoid-grid identity |
Standalone single-step cells; the caller owns the time loop and the hidden / cell state buffers. The matching buildQLSTMParams / buildQGRUParams / buildQCfCParams host helpers turn float scales into the gate-by-gate (multiplier, shift) triples.
Quantized attention + FFT
| Header | Layer | Notes |
|---|---|---|
qfft1d.hpp | QFFT1D<N> | Radix-2 DIT FFT on int16 buffers with Q1.15 twiddle factors. Scaled butterflies (shift-by-1 per stage; total 1/N) keep the working register bounded. magnitudeSquared emits int32. Inverse via conjugate trick |
qattention1d.hpp | QAttention1D | Linear (ReLU-kernel) self-attention, int8 counterpart of selfattention1d.hpp. ReLU on Q’/K’ folded into the requantizer by raising qmin = zero_point |
qattention_softmax.hpp | QAttentionSoftmax1D | Standard softmax attention. Score requantizer folds the 1 / sqrt(d_k) factor via qAttentionInvSqrt(P). Uses the same 256-entry int32 exp LUT as QSoftmax1D |
qmha.hpp | QMultiHeadLinearAttention1D | NumHeads independent QAttention1D heads run sequentially; per-head outputs stacked along the projection axis. Scratch buffers reused across heads |
See the Transformer Encoder (int8) example for an end-to-end encoder block (QLayerNorm1D → QAttention1D → QAdd → QLayerNorm1D → QDense → qrelu → QDense → QAdd).
A Minimal int8 Pipeline
#include "qaffine.hpp"
#include "qdense.hpp"
#include "qactivations.hpp"
typedef tinymind::QDense<int8_t, int8_t, int32_t, int8_t, 2, 4> Fc1;
typedef tinymind::QDense<int8_t, int8_t, int32_t, int8_t, 4, 1> Fc2;
Fc1 fc1;
fc1.weights = kFc1Weights; // host-calibrated int8 row-major
fc1.biases = kFc1Biases; // int32, scale = s_in * s_w1
fc1.input_zero_point = kInputZeroPoint;
fc1.requantizer = /* (multiplier, shift, hidden_zp, -128, 127) */;
Fc2 fc2;
fc2.weights = kFc2Weights;
fc2.biases = kFc2Biases;
fc2.input_zero_point = kHiddenZeroPoint;
fc2.requantizer = /* (multiplier, shift, logit_zp, -128, 127) */;
int8_t input_q[2], hidden_q[4], logit_q[1], output_q[1];
fc1.forward(input_q, hidden_q);
tinymind::qreluBuffer(hidden_q, 4, kHiddenZeroPoint); // ReLU = clamp at zero_point
fc2.forward(hidden_q, logit_q);
output_q[0] = tinymind::qApplyLUT(logit_q[0], sigmoidLUT);
Every value on this path is integer. The Requantizer triples and the sigmoid LUT are computed once on the host (or by an offline tool) and embedded as const data on the MCU. See PyTorch -> TinyMind int8 (XOR) for the full end-to-end example with PyTorch training, calibration, and weight emission.
Activation Functions
ReLU and ReLU6 are clamps in the integer domain. Two ways to apply them:
- Pointwise:
qreluBuffer(buf, n, zero_point)(andqrelu6Buffer(..., q_six)) loop over the buffer and clamp. - Fused:
clampForRelu(zero_point, qmin, qmax)raises the upstreamRequantizer’sqmintozero_pointso the saturation step that already runs at the end of the upstream layer covers the activation. No second pass over the buffer — this is what TFLite and CMSIS-NN do.
Sigmoid and tanh use 256-entry int8 lookup tables. The host-side builders (buildQSigmoidLUT, buildQTanhLUT) walk every int8 input value, dequantize via the input’s (scale, zero_point), apply the float reference, and requantize into the destination tensor’s grid. Runtime lookup is a single load:
int8_t sigmoidLUT[tinymind::kQActivationLUTSize]; // 256 bytes
tinymind::buildQSigmoidLUT(input_scale, input_zp,
1.0f / 256.0f, -128, // covers (0, 1) at full int8 res
sigmoidLUT);
int8_t y = tinymind::qApplyLUT(x, sigmoidLUT);
The LUTs themselves are pure data — drop them into flash on the MCU and the inference binary needs neither <cmath> nor float math.
Calibration
cpp/include/qcalibration.hpp gives you the host-side bridge from a float reference to the integer constants the deployable binary consumes. All helpers gated on TINYMIND_ENABLE_FLOAT && TINYMIND_ENABLE_STD so the deployable inference binary never pulls in float math.
Range estimation
| Helper | Purpose |
|---|---|
RangeObserver | Streaming min/max accumulator. Sweep the float model over a representative dataset |
PercentileObserver | Records every sample. rangeAtPercentile(lo_pct, hi_pct, ...) for outlier-clipped bounds. Use on heavy-tail activations (post-softmax, large-receptive-field conv) so a handful of extreme samples do not waste the int8 grid |
KLDivergenceObserver | TensorRT-style entropy calibration. Two passes (observeAbsRange, observeHistogram); computeThreshold sweeps T in [128, 2048] over a 2048-bin histogram and returns the T that minimizes KL between the clipped float distribution and its int8-quantized form. Output absmax feeds computeAffineParamsSymmetric |
Affine fit + quantize
| Helper | Purpose |
|---|---|
computeAffineParamsAsymmetric(fmin, fmax, qmin, qmax) | Activation calibration. Extends the range to include zero so zero_point lands on the grid |
computeAffineParamsSymmetric(fmin, fmax, qmax_signed) | Weight calibration. zero_point = 0, qmax_signed = 127 |
computePerChannelSymmetricScales(weights, num_channels, ...) | Per-channel weight scales for depthwise / QConv2DPerChannel |
quantize<DstStorage>(x, scale, zp, qmin, qmax), quantizeBuffer(...) | Float → int8 with std::lround rounding and saturation |
Rescaler / composition
| Helper | Purpose |
|---|---|
buildRequantizer<DstStorage>(s_in, s_w, s_out, out_zp, qmin, qmax) | Standard per-layer requantizer |
buildRescaler(s_in, s_out, out_zp, qmin, qmax) | Pure rescale (no weight component) — for QConcat2_2D / QPad2D |
buildQAddParams(s_a, s_b, s_out, out_zp, qmin, qmax) | TFLite ADD’s three (multiplier, shift) triples around a fixed left_shift |
buildQMulRequantizer(s_a, s_b, s_out, out_zp, qmin, qmax) | Elementwise multiply requantizer |
Folding + equalization
| Helper | Purpose |
|---|---|
foldBatchNorm(conv_w, conv_b, bn_gamma, bn_beta, bn_mean, bn_var, eps, ...) | Fold a Conv2D + BatchNorm pair into one fused Conv2D pre-quantization. Deployed graph never sees a BN layer |
crossLayerEqualizeDense(W1, b1, W2, in, mid, out) | Nagel-paper cross-layer equalization. Per intermediate channel c, compute r1 = max\|W1[c, :]\|, r2 = max\|W2[:, c]\|, s = sqrt(r1 / r2), scale W1[c, :] /= s; b1[c] /= s; W2[:, c] *= s. Output preserved under ReLU / identity (positively homogeneous). Zero-row channels skipped |
crossLayerEqualizeConv2D(...) | Same equalization, conv variant |
Normalization + softmax + RNN + FFT host params
| Helper | Purpose |
|---|---|
buildQBatchNormChannelParams(gamma, beta, mean, var, eps, in_scale, out_scale, ...) | Per-channel int32 triple for standalone QBatchNorm (when fold is not appropriate) |
buildQSoftmaxExpLUT(in_scale, lut_out) | 256-entry int32 exp table for QSoftmax1D |
QLSTMScales / QLSTMParams / buildQLSTMParams / quantizeQLSTMBiases | Decompose per-gate float scales into the (multiplier, shift) triples QLSTMCell consumes |
QGRUScales / QGRUParams / buildQGRUParams / quantizeQGRUBiases | Same for QGRUCell |
QCfCScales / QCfCParams / buildQCfCParams / quantizeQCfCBias / quantizeQCfCTimeBias | Build the QCfCCell requantizer triples (with ts folded into time-gate-A) and the int32 backbone / head / combined-time biases |
buildQFFTTwiddles(n, cos_out, sin_out) | Q1.15 sin/cos table for QFFT1D |
QAttention1DScales / QAttentionSoftmaxScales / qAttentionInvSqrt(P) | Score-scaling helper for softmax attention |
Typical workflow:
- Train the model in float (PyTorch, NumPy, whatever).
- Sweep a representative input set through the float forward pass; pipe each tensor’s activations through a
RangeObserver. - Call
computeAffineParamsAsymmetricper activation tensor;computeAffineParamsSymmetricper weight tensor (computePerChannelSymmetricScalesfor depthwise). quantizeBufferweights to int8; quantize biases asint32atbias_scale = input_scale * weight_scale.buildRequantizerfor each layer; emit the resulting(multiplier, shift, zero_point)triple as a constant.- (For sigmoid / tanh)
buildQSigmoidLUT/buildQTanhLUTand emit the 256-byte table as a constant. - The MCU binary defines
TINYMIND_ENABLE_QUANTIZATION=1, TINYMIND_ENABLE_FLOAT=0, TINYMIND_ENABLE_STD=0and consumes the embedded constants.
The examples/pytorch_quant/xor/ tutorial walks through the full pipeline, including the bit-identical Python lround shim that matches the C++ std::lround rounding.
Deployment Footprint
The int8 path’s flash story is roughly 4x smaller weights plus a small fixed overhead for the Requantizer tables versus a float pipeline of the same shape. RAM scales similarly for activations (int8 vs float32). Compared against the existing Q8.8 (QValue<8, 8, true>) pipeline, weights are 2x smaller and activations are 2x smaller, with the bonus that the layer-to-layer rescale lets each tensor pick its own dynamic range instead of every value sharing the Q8.8 grid.
A side-by-side comparison runs in examples/kws_cortex_m_int8/ — same MobileNet-style depthwise-separable pipeline as the float examples/kws_cortex_m/, same CSV cycle/byte report format, every layer replaced with its Q* counterpart. See the Keyword Spotting CNN (int8) walkthrough for what the numbers look like.
SIMD acceleration
ISA-capability-gated SIMD specializations live inside the inner reduction loop of QDense, QConv2D, and QConv2DPerChannel. Every gate defaults to 0; with all gates off the layer bodies fall back to a scalar dispatch that emits byte-identical output to the scalar reference. Backend precedence: x86 AVX512_VNNI > AVX512F > AVX_VNNI > AVX2 > scalar; Arm NEON_DOTPROD > NEON > SVE > HELIUM_MVE_I > scalar. The orthogonal TINYMIND_ENABLE_OPENMP=1 gate adds outer-loop parallelism on the output-filter axis. See SIMD Backends for the gate matrix, prerequisite chain, bit-exactness invariant, and the examples/perf_matrix/ bench harness.
Mixed precision and fp16 storage
cpp/qbridge.hpp provides pointwise converters at layer boundaries between the int8 affine pipeline, the QValue Q-format pipeline, float, and a software half-precision storage tier (affineDequantize / affineQuantize, qValueToFloat / floatToQValue, qValueToAffine / affineToQValue, plus fp16 / bf16 counterparts when TINYMIND_ENABLE_FP16=1). This is what enables hybrid pipelines like int8 affine CNN frontend → fp16 attention head → int8 classifier. See Mixed Precision for the converter list, the fp16/bf16 storage tier, and the mixed_precision_kws exemplar.
Importer tooling
Two host-side importers in apps/ consume already-trained float / QDQ models and emit a TinyMind-format weights.hpp that snaps into the Q* layer family. Per-layer calibration picks any of MinMaxObserver / PercentileObserver / KLDivergenceObserver; Conv2D-then-BatchNorm2D pairs auto-fuse via foldBatchNorm before quantization.
apps/import_pytorch/tinymind_import.py— caller assembles layer descriptors from atorch.state_dictand a numpy forward callable. No PyTorch dependency at module import.apps/import_onnx/tinymind_import_onnx.py— QDQ-format ONNX importer. WalksQuantizeLinear/DequantizeLinear/QLinearConv/QLinearMatMulfrom a model produced byonnxruntime.quantization.quantize_static. Theonnxpackage is imported lazily so the emitter half is usable without it.
The PyTorch → TinyMind int8 (importer) walkthrough runs the full flow end-to-end with examples/import_demo/.
What Is Not Included
The int8 path is intentionally minimal:
- No quantization-aware training (QAT) — post-training only. The expectation is that you train in your favorite float framework and import.
- No int4 quantization — int8 weights, int8 activations, int32 accumulators. (Mixed precision is supported via the
qbridge.hppconverters into theQValueQ-format pipeline and thefp16_t/bf16_tstorage tier — see Mixed Precision.) - No whole-graph conv+bn+relu auto-fusion pass — each layer is standalone. ReLU folds into the upstream
RequantizerviaclampForRelu; Conv2D + BatchNorm fuses pre-quantization viafoldBatchNorm. The library never walks the graph to do this for you — the importer / caller stitches the fused weights together at calibration time. - No runtime CPU dispatch — SIMD gates are compile-time; the library compiles for one ISA per build. Fat-binary dispatch is the caller’s problem.
Tests and Examples
Tests
unit_test/quantization/— Boost.Test suite. CoversRequantizerround-trip; per-tensor and per-channel calibration;QConv2D/QConv2DPerChannel/QDepthwiseConv2D/QPointwiseConv2D/QPool2D/QDensefloat parity; sigmoid / tanh LUT builders;foldBatchNormparity vs unfused conv→BN;QBatchNorm2D/QLayerNorm1D/QSoftmax1Dparity;QLSTMCell/QLSTMCellint16-state drift /QGRUCell/QCfCCell; Q1.15 twiddle /QFFT1Dmagnitude + round-trip /QAttention1D/QAttentionSoftmax1D/QMultiHeadLinearAttention1D; SIMD dispatch parity, INT8 extreme-value patterns,activeBackendName();PercentileObserver+KLDivergenceObserver+crossLayerEqualize*.unit_test/embedded/— Eight-corner cross-build matrix:freestanding,no_stdlib,no_fpu,hosted,quant_freestanding,fp16_freestanding,int16_accum_freestanding,simd_disabled. Plus asimd_prereq_regressionsmake target locking the static_assert prerequisite chain via compile-failure checks.unit_test/integration/— Golden-byte suite. One fixture per exemplar shells out tomake goldenand asserts the int8 byte stream matches a baked-in expected string. Catches silent regressions in the inference path regardless of which SIMD backend dispatch resolves to.
Examples
examples/pytorch_quant/xor/— End-to-end PyTorch training + per-tensor calibration +weights.hppemission + pure-integer C++ inference. Good entry point.examples/kws_cortex_m_int8/— Full MobileNet-style depthwise-separable pipeline in int8, with a CSV cycle/byte report directly comparable to the floatkws_cortex_m.examples/resnet_block_int8/— int8 residual block:QPad2D→QConv2DPerChannel→qrelu→QPad2D→QConv2DPerChannel→QAddskip →qrelu. Reports max-abs error vs the float reference.examples/transformer_encoder_int8/— int8 transformer encoder block (LayerNorm + linear attention + Add + LayerNorm + Dense + ReLU + Dense + Add). ~2% max-abs error vs the float reference on the bundled dataset.examples/perf_matrix/— SIMD bench. Builds the same int8QConv2D+QDenseblock under each enabledTINYMIND_ENABLE_SIMD_*combination and emits one CSV row per backend withoutput_checksum(invariant across backends) and per-call timing.examples/import_demo/— Importer end-to-end. C++ binary exercisesRangeObserver+PercentileObserver+KLDivergenceObserver+crossLayerEqualizeDenseon a deterministic 3-8-4-2 MLP;demo.pydrivesapps/import_pytorch/tinymind_importfrom a realtorch.state_dict.examples/resnet18_block_int8/— int8 ResNet-18-shaped stem + one basic-block stage.make run/make bench/make golden.examples/mobilenetv2_int8/— int8 MobileNetV2-shaped pipeline: stride-2 stem + stride-1 inverted-residual block with skip + stride-2 inverted-residual block + GAP + dense.examples/mixed_precision_kws/— int8QDensefrontend →affineI8ToFp16bridge → fp16 linear-attention head with residual + mean-pool →fp16ToAffineI8bridge → int8 classifier. RequiresTINYMIND_ENABLE_FP16=1.
See Also
- SIMD Backends — capability-gated SIMD specializations.
- Mixed Precision — qbridge converters + fp16/bf16 storage tier.
- Quantized Networks (Binary / Ternary) — extreme-quantization siblings; pick this path when you need 32x compression and a multiply-free MAC.
- Q-Format (Fixed-Point) — the existing
QValuepipeline. Affine quantization composes with this viaqbridge.hpp;QValuepredates the int8 path. - PyTorch Interoperability — float / Q-format weight import. For the int8 path, see PyTorch → TinyMind int8 (importer).