SIMD Backends
TinyMind ships ISA-capability-gated SIMD specializations in the inner reduction loop of the int8 affine layer family (QDense, QConv2D, QConv2DPerChannel). The library never sniffs the CPU. Every backend lives behind a TINYMIND_ENABLE_SIMD_* preprocessor gate, every gate defaults to 0, and with all gates off the layer bodies fall back to a scalar dispatch that emits byte-identical output to the scalar reference.
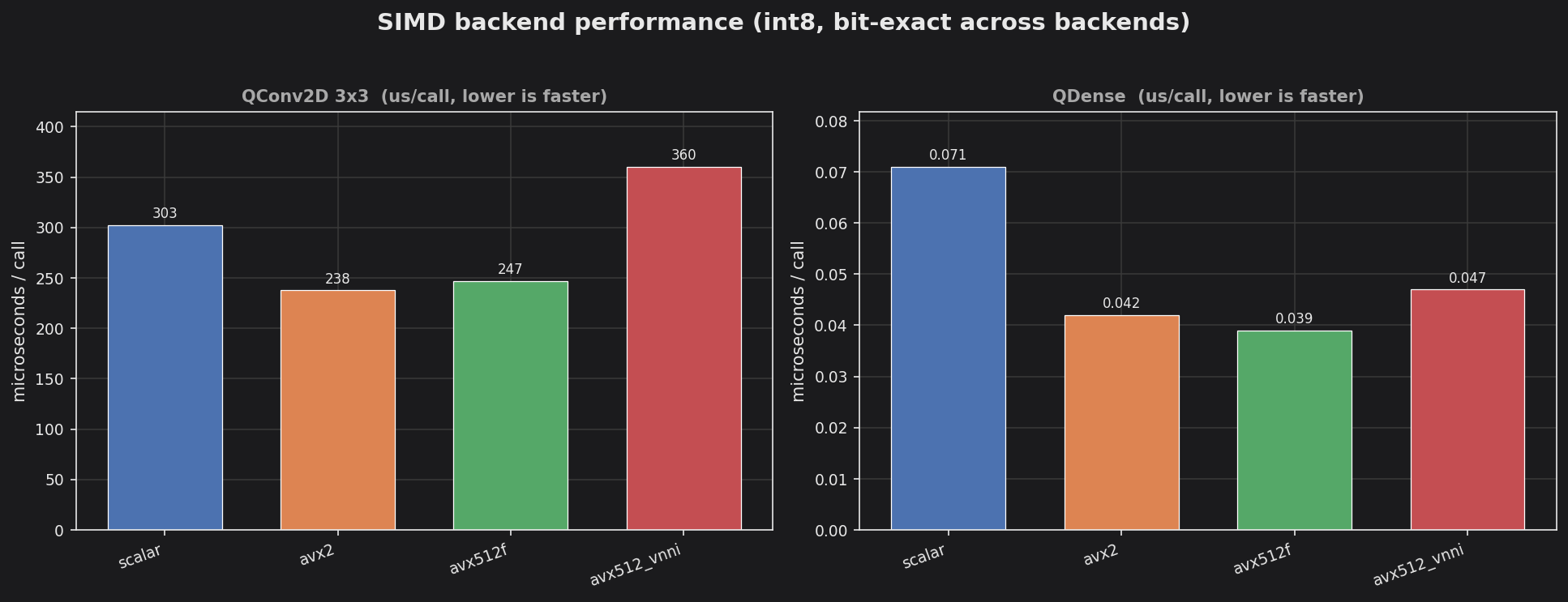
examples/perf_matrix (make report && make plot): per-call throughput across backends. The output_checksum is identical across all of them — the speedup is free of any numerical change.
Design rules
- Gates name ISA extensions, never CPU models. A Cortex-A55 configured without NEON simply does not set
SIMD_NEON=1; the library has no Cortex-A55 special case. - Compile-time only. No
cpuid,getauxval,__builtin_cpu_supports, or#ifdef __ARM_NEONauto-detection in library headers. The build system translates-march=flags into matchingTINYMIND_ENABLE_SIMD_*=1defines. Fat-binary dispatch is the caller’s problem. - Bit-exactness on the integer paths. Every integer SIMD backend is bit-exact with the scalar reference: int8 × int8 products fit in int16, accumulation preserves full int32 precision regardless of lane order, and the zero-point correction is folded into the final scalar subtract. Float SIMD reductions (
SIMD_NEON_FP16,SIMD_HELIUM_MVE_F) are not bit-exact with scalar — the invariant applies only to the integer paths. - Scalar fallback is the deployable freestanding default.
unit_test/embedded/Makefilebuilds asimd_disabledcorner (everySIMD_*=0,QUANT=1 FLOAT=0 STD=0) to lock the byte-identical invariant at the deployable shape.
Gate matrix
All default 0. Set both the gate and the matching -march= flag.
| Gate | ISA extension | Notes |
|---|---|---|
TINYMIND_ENABLE_SIMD_NEON | Armv8-A NEON (Adv. SIMD) | Baseline Arm 128-bit vector path |
TINYMIND_ENABLE_SIMD_NEON_DOTPROD | NEON + FEAT_DotProd | Armv8.2-A sdot / udot. Highest int8 throughput on Cortex-A55 / A76 / A510 / A710 / A715 |
TINYMIND_ENABLE_SIMD_NEON_FP16 | NEON + FEAT_FP16 | Armv8.2-A vector half-precision arithmetic. Used by mixed_precision_kws |
TINYMIND_ENABLE_SIMD_SVE | Scalable Vector Extension | Width-agnostic, predicate-driven |
TINYMIND_ENABLE_SIMD_SVE2 | SVE2 | Adds the int8 dot-product instructions Arm’s server-class cores ship |
TINYMIND_ENABLE_SIMD_HELIUM_MVE_I | Armv8.1-M Helium MVE-I | M-profile integer vector (Cortex-M55 / M85). Mutually exclusive with NEON / SVE |
TINYMIND_ENABLE_SIMD_HELIUM_MVE_F | Armv8.1-M Helium MVE-F | M-profile float vector. Same exclusivity rule |
TINYMIND_ENABLE_SIMD_AVX2 | x86 AVX2 | 256-bit baseline. Avoids PMADDUBSW (saturates on pair-sum) |
TINYMIND_ENABLE_SIMD_AVX_VNNI | AVX2 + AVX-VNNI | Tiger Lake / Alder Lake / Raptor Lake — VPDPBUSD over 256-bit vectors |
TINYMIND_ENABLE_SIMD_AVX512F | AVX-512 Foundation | 512-bit baseline |
TINYMIND_ENABLE_SIMD_AVX512_VNNI | AVX-512 + VNNI | Ice Lake / Sapphire Rapids — VPDPBUSD over 512-bit vectors. Highest int8 throughput on x86 server-class |
TINYMIND_ENABLE_OPENMP | OpenMP runtime | Orthogonal to every SIMD gate. Parallelizes the output-filter loop in QConv2D / QConv2DPerChannel via TINYMIND_PARALLEL_FOR_OUTER in cpp/include/threading.hpp. Caller passes -fopenmp separately |
Prerequisite chain
Each cpp/include/simd/simd_*.hpp header opens with a static_assert enforcing Arm’s documented dependency table:
DOTPRODrequiresNEONSVE/SVE2requireNEONFP16(vector) requiresNEONAVX_VNNIrequiresAVX2AVX512_VNNIrequiresAVX512FHELIUM_MVE_IandHELIUM_MVE_Fare M-profile only — mutually exclusive withNEONandSVE
Misconfiguration like DOTPROD=1, NEON=0 fails at compile time with a readable message. The simd_prereq_regressions make target in unit_test/embedded/Makefile locks the regression by checking that misconfigured builds fail.
Backend precedence
The public entry point is tinymind::simd::int8DotWithZeroPoint in cpp/include/simd/simd_dispatch.hpp, plus a templated dotProductWithZeroPoint<Input, Weight, Accum> that specializes on int8_t / int8_t / int32_t. When multiple gates are enabled in the same build, dispatch resolves to the strongest:
- x86:
AVX512_VNNI > AVX512F > AVX_VNNI > AVX2 > scalar - Arm:
NEON_DOTPROD > NEON > SVE > HELIUM_MVE_I > scalar
tinymind::simd::activeBackendName() returns the resolved choice as a const char* for benchmark reports.
Bit-exactness invariant — why it matters
The integer SIMD backends produce byte-identical output to the scalar reference for any input. The integration suite (unit_test/integration/) leans on this: each exemplar’s make golden mode emits an int8 byte stream, and the integration test asserts that stream matches a baked-in expected string. Because the inference path is deterministic and the SIMD backends are bit-exact, the same expected string passes regardless of which gate combination the example binary was built with. Any silent drift in qaffine.hpp, qcalibration.hpp, or any SIMD specialization that claims bit-exactness trips the test.
The AVX2 backend deliberately avoids PMADDUBSW: that instruction saturates on the pair-sum step, which would break the bit-exactness guarantee on pathological inputs. AVX-VNNI and AVX-512-VNNI use the canonical uint8-shift trick so VPDPBUSD reduces a uint8 / int8 product exactly.
Bench harness — examples/perf_matrix/
The bundled bench builds the same int8 QConv2D 3x3 + QDense block under each enabled gate combination and emits a single CSV per binary:
active_backend,conv_iters,conv_total_us,conv_us_per_call,
dense_iters,dense_total_us,dense_us_per_call,
conv_output_checksum,dense_output_checksum
output_checksum is invariant across backends when the bit-exactness invariant holds — any disagreement is a backend bug.
cd examples/perf_matrix
make # builds scalar / avx2 / avx512f / avx512_vnni (default x86 set)
make report # runs every binary, writes output/perf_report.csv
To bench an Arm gate, add a cross-target with the matching compiler:
neon_dotprod:
$(MKDIR)
aarch64-linux-gnu-g++ $(OPT) $(WARN) -march=armv8.2-a+dotprod \
-o ./output/perf_matrix_neon_dotprod $(SOURCES) $(INCLUDES) \
$(DEFINES) -DTINYMIND_ENABLE_SIMD_NEON=1 \
-DTINYMIND_ENABLE_SIMD_NEON_DOTPROD=1
Run the resulting binary on the target hardware (or under qemu-aarch64 for correctness checks).
What about non-int8 layers?
TinyMind specializes the int8 affine layer family because that is where the integer dot product wins big. The Q-format pipeline (QValue<Q, F, signed>) and float pipeline rely on compiler auto-vectorization with -O3 -march=native — no library-side specialization. The SIMD_NEON_FP16 and SIMD_HELIUM_MVE_F float gates land via cpp/include/simd/simd_neon_fp16.hpp, used by the mixed-precision exemplar.
See Also
- Int8 Affine Quantization — the layer family these backends accelerate.
- Mixed Precision — qbridge + fp16 storage, the consumer of the float vector gates.
examples/perf_matrix/— bench source.cpp/include/simd/— backend headers (one per capability).