Elman Network — Temporal XOR
The textbook demonstration of what a recurrent (Elman) network buys you: memory a plain feed-forward network does not have. The same task is trained on both an ElmanNeuralNetwork and a feed-forward NeuralNetwork of the same shape, in Q16.16 fixed-point, so the only variable is the recurrent connection.
How it works
- A stream of random bits
x[0], x[1], ...is fed one per timestep. The target at steptistarget[t] = x[t] XOR x[t-1](withx[-1] = 0). - The network only ever sees
x[t]— neverx[t-1]. So for any given input bit the correct answer is 0 or 1 with equal probability depending on history a memoryless model cannot observe. A plain MLP cannot beat chance; its best response to each input is 0.5. An Elman network has a recurrent hidden context that can holdx[t-1], so it recovers the XOR. - Both nets are 1 input → 8 hidden (tanh) → 1 sigmoid output, Q16.16 fixed-point with
GradientClipByValue, trained for 60 passes over a fixed 2000-bit stream. The only difference is that the Elman hidden layer feeds its previous-step context back to itself. - A plain Elman/recurrent network exposes no public state reset (only the gated
LstmNeuralNetwork/GruNeuralNetworkdo), so the recurrent context flows continuously; temporal XOR only needs one step of memory, so this is harmless. At evaluation one warm-up bit is fed before scoring to align the context with theprevbit the target depends on.
Build and run
cd examples/elman_temporal_xor
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
make run writes output/elman_temporal_xor.csv with columns step,input,target,elman,mlp and prints the held-out accuracy of each network over a fresh 599-bit stream.
Output
Held-out accuracy (599 bits):
Elman (recurrent) : 98.33%
MLP (no memory) : 51.09%
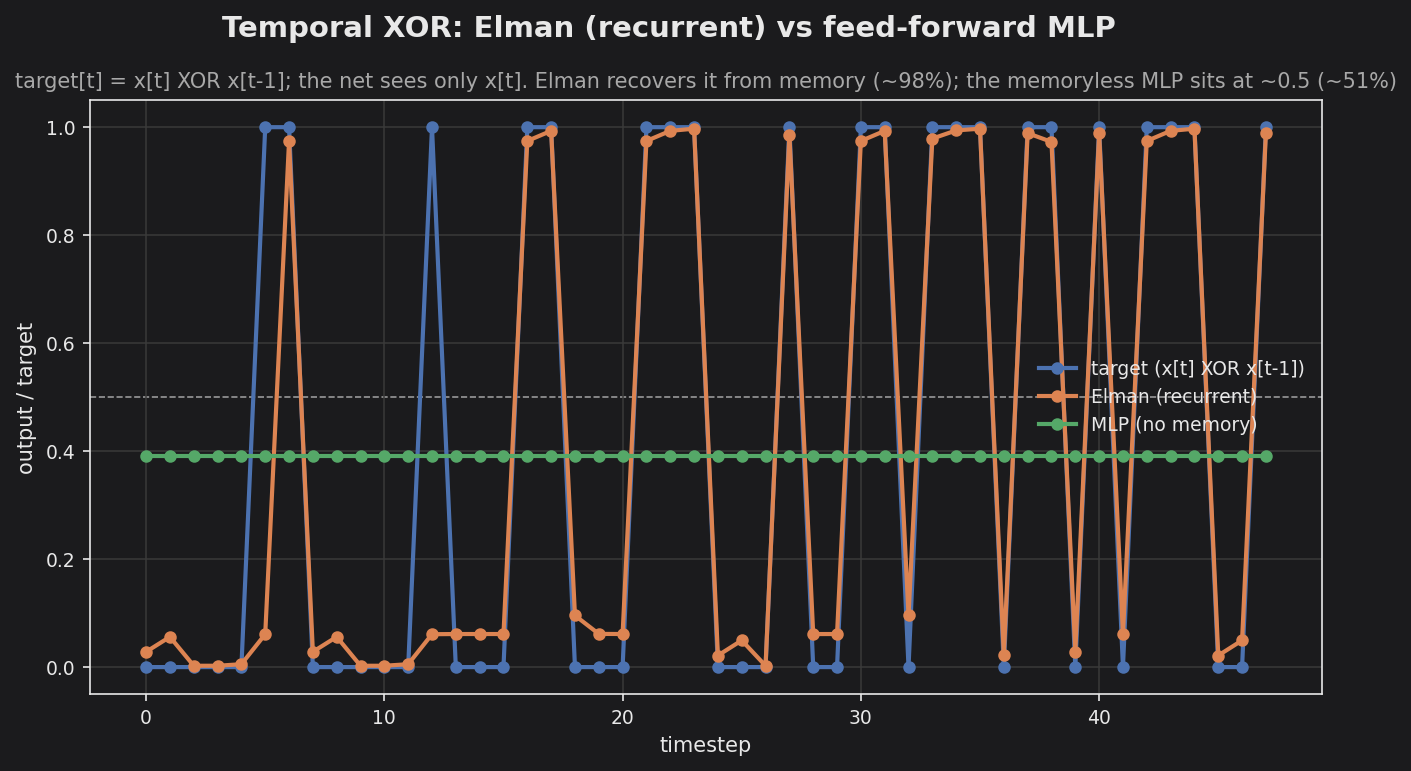
The Elman output (orange) snaps to the 0/1 target as it recovers x[t] XOR x[t-1] from its recurrent memory, while the MLP output (green) is pinned near the dashed 0.5 line — with no access to x[t-1] it can only output the mean. The recurrent connection is the whole difference. The few Elman misses are the residual ~1.8%; the task is learnable but the small fixed-point net does not reach a perfect fit.