Optical Handwritten Digits
A ten-way handwritten-digit classifier trained on the UCI Optical Recognition of Handwritten Digits dataset, where each sample is an 8×8 bitmap (64 pixels, intensity 0..16) downsampled from a 32×32 scan.
How it works
- Q16.16 fixed-point MLP, 64 → 32 → 10, ReLU hidden layer and 10 sigmoid outputs (one-hot, predicted class is the argmax).
- The same
NeuralNet<>fixed-point train-and-deploy path as Iris, scaled up to a real 64-feature image classification task with a 10-class output. - Each pixel is per-feature z-score normalized then scaled by 1/3; because many border pixels are constant zero, the normalizer guards
stdev < 1e-6and maps those features to a constant 0 input. 60k iterations of uniform sampling from the training split.
Build and run
cd examples/optical_digits
make release
make run
make plot # needs matplotlib; a venv/pyenv works if it is not already in your Python
Both data files ship with the example — optdigits.tra (3823 train rows) and optdigits.tes (1797 test rows) — and the Makefile copies them into ./output/ before the run, so there is nothing to download.
Output
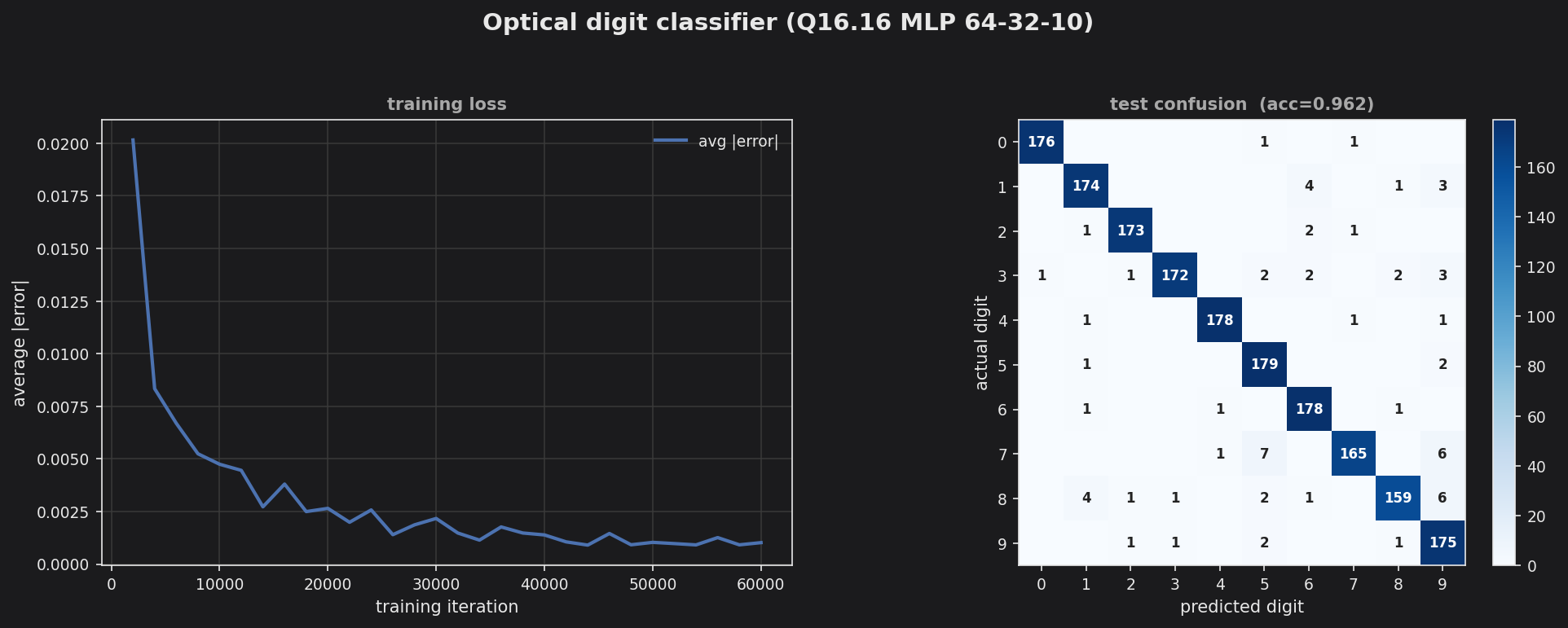
The loss converges to ~0.001 average error and the confusion matrix is strongly diagonal, giving ~96% test accuracy (1729/1797). The residual off-diagonal mass is the expected hard cases — 7s read as 5s/9s, a few 8s read as 1s — pairs that are genuinely ambiguous at 8×8 resolution.
Sample predictions
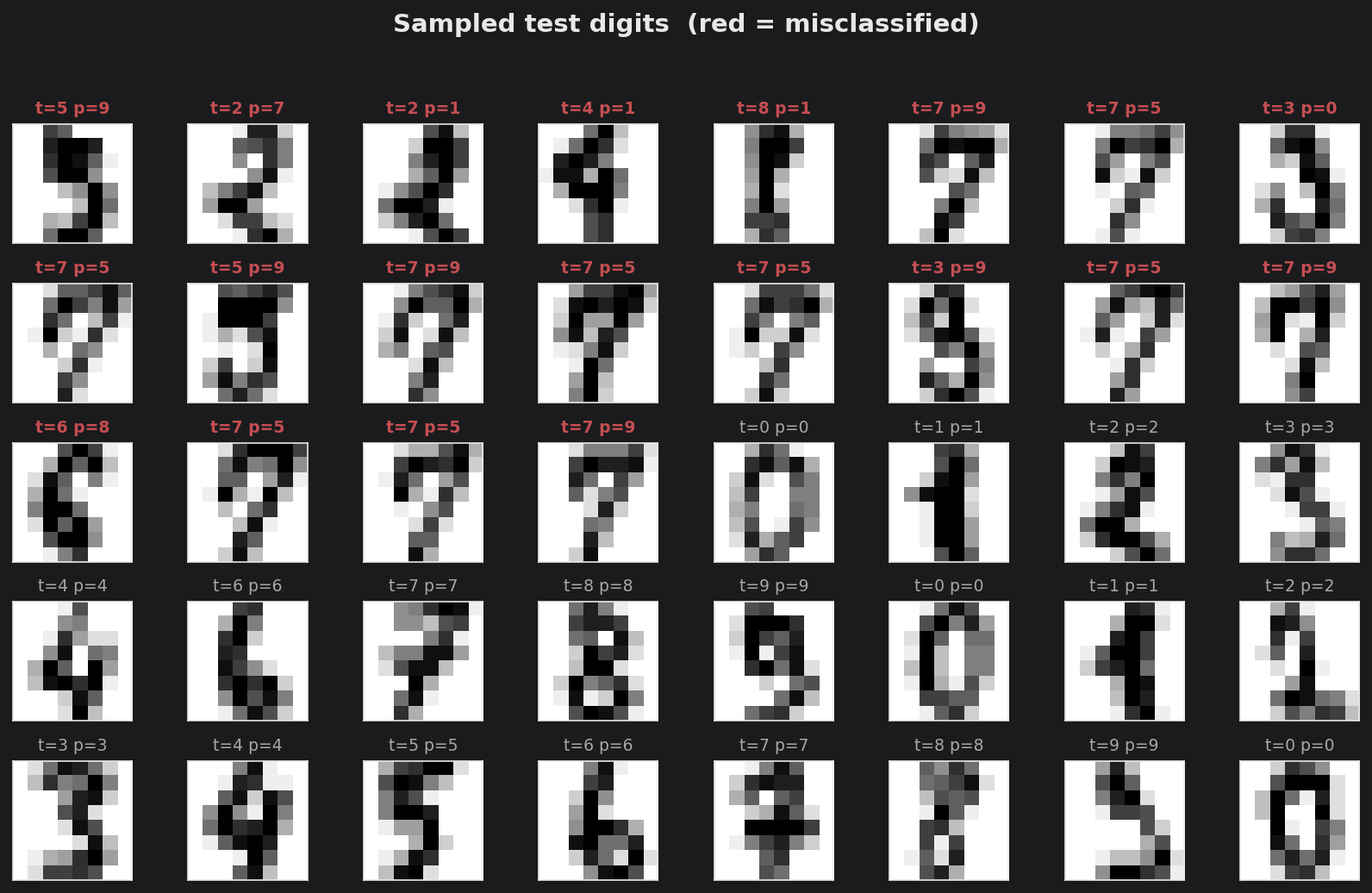
Each tile is a sampled test image titled t=<true> p=<pred>, red when misclassified — a direct look at what the fixed-point net gets right and where it slips on the low-resolution glyphs.