TinyMind for Physics-Informed Neural Networks
This page assesses how TinyMind could be used to build or deploy Physics-Informed Neural Networks (PINNs). It combines an audit of the current library against PINN requirements with a survey of the relevant literature.
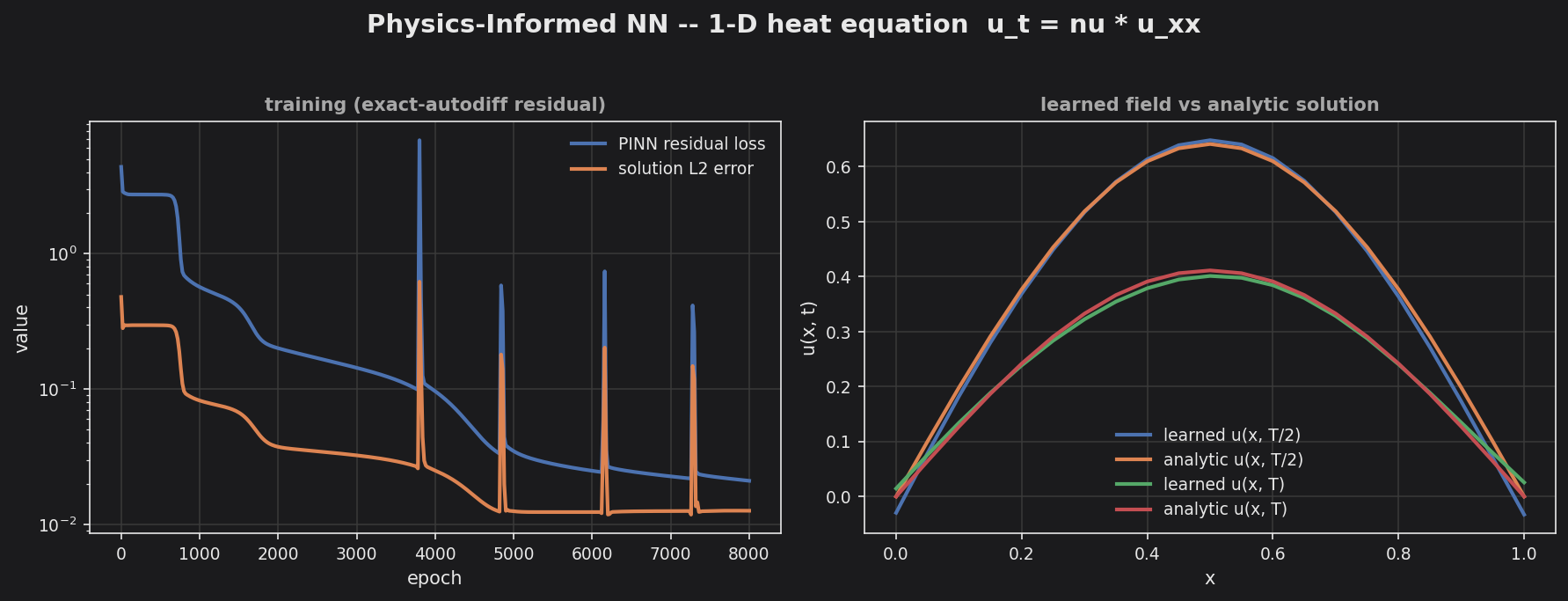
examples/pinn_heat1d (make train): exact-autodiff residual training drives the loss / solution-L2 error down (left) until the learned field matches the analytic solution (right).
Verdict
TinyMind now ships the load-bearing PINN primitive — forward-mode automatic differentiation of a field with respect to its input coordinates — for every value type, fixed-point included. This was originally the one capability gap (backpropagation computes ∂Loss/∂weights, the wrong derivative for a PDE residual). It is closed by cpp/dual.hpp and cpp/dualActivations.hpp, and demonstrated end-to-end by examples/pinn_heat1d/.
Training a PINN means composing those input derivatives with the residual’s gradient w.r.t. the weights. That is ordinary host code — “on-device” refers to the eventual deployment footprint, not a build requirement, so the training loop is written, run, and verified on a workstation like any other code. examples/pinn_heat1d/ --train does exactly this: it fits a small MLP to the heat equation on the host (exact-autodiff residual, finite-difference weight gradients), driving the PINN loss down ~370x with no device involved. Inference of a trained PINN then runs through the existing double or Q-format forward pass. The only thing still open is an efficient weight-gradient path (reverse-over-forward) for larger models — an optimization, also host-side.
Status (update): Sections 1–2 below describe the original gap and its resolution. The dual-number machinery they call for is now in the tree and tested (
unit_test/dual/, plus a freestandingDual<QValue>check inunit_test/embedded/). The end-to-end PINN path is gated too:unit_test/pinn/assertsPinnMlpforward / input-derivative / weight-gradient parity,sgdStep↔sgdStepReverseagreement, and 1-D heat-equation residual convergence below a fixed threshold — the automated counterpart of thepinn_heat1d --trainexample. The “Concrete next steps” section marks what is done versus what is left.
1. What a PINN requires, and where TinyMind stands
A PINN’s loss is the residual of a partial differential equation: a differential operator applied to the network output u(x, y, z, t) with respect to its input coordinates, frequently to second order or higher (for example ‖∂²u/∂x² − f‖² for a diffusion equation). Solving a PDE with a PINN therefore fundamentally requires derivatives of the network output with respect to its inputs.
| PINN requirement | TinyMind status | Notes |
|---|---|---|
| Differentiate output w.r.t. inputs | Present (cpp/dual.hpp) | Forward-mode Dual<ValueType>; ∂u/∂x in one pass. Was the original gap. |
| 2nd- and higher-order input derivatives | Present (nested Dual) | Dual<Dual<…>> gives ∂²u/∂x² etc.; verified for polynomials and tanh. |
| Smooth activation (C² or better) | Present | tanh, sigmoid, ELU, GELU with analytic derivatives; tanh(Dual)/sigmoid(Dual) overloads in cpp/dualActivations.hpp. ReLU unsuitable (2nd derivative ≡ 0). |
| Small network sizes | Present | PINNs are typically small MLPs; TinyMind targets embedded-scale models. |
| Fixed-point / int8 inference | Present | Q-format and int8 pipelines run a plain forward pass of u(x, t). |
| Residual-loss training (∂residual/∂weights) | Not yet | Composing input-derivative AD with weight gradients; see next steps. |
The takeaway: TinyMind now ships the correct activation family, the correct size class, and the input-space differentiation operator. The remaining work is the training loop, not the derivatives.
2. The missing piece: forward-mode / Taylor-mode autodiff
The standard and efficient way to obtain a PINN’s input derivatives is forward-mode automatic differentiation, implemented with dual numbers:
a + bε with ε² = 0 ⟹ f(a + ε) = f(a) + ε·f′(a)
Forward-mode cost scales with the input dimension, and PINNs have only about 1–4 inputs (x, y, z, t), so it is the natural choice. It is realized purely by operator overloading on a dual-number type — a clean fit for a header-only C++ template library.
- Higher orders (for second-order PDEs) come from Taylor-mode AD, a generalization that carries higher polynomial terms (
f(a + ε) = f(a) + ε·f′(a) + ½ε²·f″(a) + …). Naive nesting of first-order AD blows up exponentially in the differentiation order; Taylor-mode avoids that. - Header-only C++ is proven feasible. Boost.Math Autodiff is exactly this — forward-mode, Taylor-series basis, Nth derivative. TinyMind’s test Makefiles already set
BOOST_HOME. - State-of-the-art PINNs already use it. Separable PINNs (SPINN) use forward-mode AD for the residual; STDE uses Taylor-mode for high-order operators.
Fit to TinyMind’s design
A Dual<ValueType> type, templated the same way as QValue, slots directly into TinyMind’s policy-based design. Because the activation policies already expose analytic derivatives, propagating a dual number through the network by the chain rule is straightforward.
This is now implemented. cpp/dual.hpp provides Dual<ValueType> (value + derivative, sum/product/quotient rules, a chainRule hook) built purely from the value type’s arithmetic, so it works identically for float/double and QValue — and is freestanding-clean (no <cmath>/STD/FLOAT required, so fixed-point input derivatives run on an MCU). cpp/dualActivations.hpp adds tanh(Dual) / sigmoid(Dual), with a DualScalarActivation<V> policy that isolates the one type-specific step (LUT for QValue, std::tanh for double) and recurses through nested duals for higher-order derivatives. cpp/dualmath.hpp adds exp / sin / cos / sqrt on the same pattern (sin/cos/exp for float/double, unblocking SIREN-style fields and trig/exp source terms; sqrt for every type including QValue). Mixed partials (d²u/dx dy) come from seeding different directions at each nesting level.
3. Precision: the real risk
PINN training is precision- and conditioning-sensitive. Published evidence shows that even FP32 — far above int8 or fixed-point — can cause the L-BFGS optimizer to prematurely satisfy its convergence test and freeze the network in a spurious “failure phase” where solution error stays large.
Two important boundaries on that evidence (claims that did not survive adversarial verification during this research):
- The claim that FP64 eliminates PINN failure modes was refuted.
- The claim that precision is the cause of failures (rather than optimization difficulty) was refuted.
So treat “low precision hurts PINN training” as well-supported directionally, but not as “more precision is a guaranteed fix.”
Largest open gap in the literature: no published benchmark of int8 or fixed-point PINN accuracy — training or inference — was found. The viability of TinyMind’s Q-format pipeline for PINN inference is therefore plausible but empirically unproven. This is a genuine research opportunity, not a settled result.
4. Realistic deployment pattern (two stages)
Stage 1 — HOST: train PINN (autograd over inputs for the PDE residual), export weights
Stage 2 — inference only, plain forward pass u(x, t). Two precision options:
(a) double -> double exact, no quantization error
(b) double -> Q-format small quantization error
Deploying a trained PINN needs no autodiff at inference — it is just evaluating u(x, t). Two supported precision paths, both verified in examples/pinn_heat1d/:
- (a) double → double. Train in
double, infer indouble. Zero quantization error — inference reproduces the trained field bit-faithfully (the exemplar’s double inference matches the analytic field to 0.0). Still header-only, no OS, no GPU. TinyMind’sNeuralNet<double>already trains and infers in double (see the floating-point NN unit tests), so this path needs nothing new. The simplest and most accurate option. - (b) double → Q-format. Same field in Q16.16 fixed point agrees with the double reference to ~1.7e-3 on the exemplar grid. Use when the accuracy budget allows trading precision for fixed-point arithmetic.
What gates this — and what does not
The double path is gated only by the capability macros -DTINYMIND_ENABLE_FLOAT=1 (use float/double as the value type) and -DTINYMIND_ENABLE_STD=1 (for the std::tanh/std::exp activation evaluation). There is no FPU build switch. TINYMIND_ENABLE_FLOAT is a capability gate, not a hardware assertion: it compiles and runs on a target without an FPU too — the compiler simply emits soft-float (correct, just slower). Whether hardware float is used is a toolchain matter (-mfpu=, -mfloat-abi=), orthogonal to TinyMind’s macros.
So the practical guidance is about performance, not buildability: prefer path (a) on targets with an FPU (where double is cheap) and path (b) on no-FPU MCUs (where soft-float double would be slow and fixed-point is the better trade). Both compile from the same headers; only the value type and the two capability macros differ. The fixed-point Dual arithmetic in cpp/dual.hpp itself needs neither macro and runs in the fully freestanding build.
- Now possible: the residual itself (input derivatives) can be computed in float or fixed-point via
Dual— at training time on the host, and even at inference time on-device for residual monitoring or adaptive sampling, with no host autograd. Training (the residual’s gradient w.r.t. the weights) is host code and is demonstrated byexamples/pinn_heat1d/ --train.
5. The KAN angle (promising, under-explored)
TinyMind already ships B-spline / KAN layers with derivatives (cpp/bspline.hpp). Physics-informed KANs (PIKANs) are well-suited to small models. An open question worth probing: can TinyMind’s existing spline-derivative machinery be repurposed to compute input-coordinate derivatives for the PDE residual (rather than weight gradients)? If so, it could be a shortcut to PINN support via the KAN path. This branch is currently unverified.
Concrete next steps for TinyMind
Done:
- ✅
Dual<ValueType>forward-mode type — header-only, value-type-generic, freestanding-clean (cpp/dual.hpp), validated fordoubleandQValue. - ✅
tanh(Dual)/sigmoid(Dual)activation overloads (cpp/dualActivations.hpp), giving∂u/∂xdirectly through a smooth field. - ✅ Higher-order derivatives via nested
Dual<Dual<…>>(∂²u/∂x²), verified against the analytictanh''. - ✅ 1-D exemplar (
examples/pinn_heat1d/): the heat residualu_t − ν·u_xxby forward-mode AD — residual ≈ 0 on an exact solution, and autodiff derivatives match finite differences on a nonlineartanhfield. - ✅ Host PINN training loop (
examples/pinn_heat1d/ --train): fits a small MLP to the heat equation with the exact-autodiff residual and finite-difference weight gradients; drives the PINN loss down ~370x and the solution L2 error to ~1% — all host-side, no device. - ✅ Elementary
Dualmath (cpp/dualmath.hpp):exp/sin/cos/sqrtwith analytic derivatives + nested-recursion (SIREN fields, trig/exp source terms), and mixed partials (d²u/dx dy) via per-level seed directions. - ✅ QValue
exp/sin/cosduals wired to the fixed-point lookup tables (DualScalarMath<QValue>);exp/sin/cos/sqrtduals now work forfloat,double, and fixed-point alike. - ✅ Exact one-pass weight gradients via vector forward-mode (
cpp/multidual.hpp,MultiDual<V,N>): seeds all weights as tangents and returns the full loss gradient in a single forward pass — no finite-difference step error.cpp/pinn.hppadds a reusable Dual-differentiablePinnMlpand a PDE-agnosticsgdSteptrainer core built on it.examples/pinn_heat1d/ --trainnow trains with these (loss ~50x down, solution L2 ~2.5%). -
✅ Fixed-point residual benchmark (
--traintail): with the trained weights quantized to Q16.16, the residual computed in fixed point (tanh + dual derivatives via the LUTs) matches thedoubleresidual to ~6e-3 — soDual<QValue>is accurate on a real residual, not just mechanically correct. -
✅ Stock
NeuralNet<>input-differentiability viatinymind::pinn::forwardAs(cpp/pinn.hpp): an ADDITIVE free function that re-evaluates a trained single-hidden-layer feed-forward network in any scalar type by reading its weights through the public getters — no change to the network’s own forward / train / storage, so the byte-exact golden and embedded regressions are untouched. Withdoubleit reproducesgetLearnedValues; withDual<double>it yields the network’sdu/dx, verified against finite difference (unit_test/nn). (Note: introducingtinymind::sin/tanh/etc. means unqualified transcendental calls insidenamespace tinymindnow resolve to them; qualify such callsstd::— one occurrence in the test suite was fixed.) - ✅ True reverse-mode weight gradients (
cpp/revdual.hpp,RevVar): a tape-based adjoint scalar whose one backward pass yields the gradient w.r.t. all leaves regardless of count. Composes underDual<>for reverse-over-forward (residual input-derivatives forward-mode, weight gradient reverse-mode in one backward pass);pinn::sgdStepReverseis the reusable reverse-mode trainer step. Host-only (heap tape, gatedFLOAT && STD) — the large-net option;MultiDualstays the freestanding-friendly default. - ✅
forwardAsextended to any number of uniform-width hidden layers (e.g.MultilayerPerceptron); validated against native forward on a 2→4→4→1 net. - ✅ Ergonomic Taylor-mode (
cpp/taylor.hpp,Jet<V,Order>): arbitrary-order single-variable derivatives in one sweep (no nesting blow-up), validated to 4th order forsin/exp/polynomials and 3rd order fortanh/sqrt.
Remaining (minor, none blocking): variable-width HiddenLayers<...> in forwardAs (needs per-layer widths the public API doesn’t expose); multi-variable high-order Taylor (the Jet is single-variable). Both are niche extensions, not gaps in PINN support.
Caveats and sources
The forward-mode and Taylor-mode AD mathematics is settled textbook material (high confidence). The PINN speedup figures (SPINN, STDE) are best-case results for specific PDEs, not universal constants. The precision finding rests on a single 2025 source whose strongest implications were refuted. No quantized-PINN benchmark exists, so the int8-inference conclusion here is inferred from general PINN precision-sensitivity plus TinyMind’s design, not measured.
Primary sources:
- Cuomo et al., “Scientific Machine Learning through PINNs,” J. Sci. Comput. 2022 — https://link.springer.com/article/10.1007/s10915-022-01939-z
- Dashtbayaz et al., IJCAI 2024 — https://arxiv.org/abs/2405.01680
- Cho et al., “Separable PINN” (SPINN), NeurIPS 2023 — https://arxiv.org/pdf/2306.15969
- Shi et al., “Stochastic Taylor Derivative Estimator” (STDE), NeurIPS 2024 — https://arxiv.org/pdf/2412.00088
- Bettencourt et al., “Taylor-mode AD” (JAX), NeurIPS 2019 workshop — https://openreview.net/pdf?id=SkxEF3FNPH
- Boost.Math Autodiff — https://www.boost.org/doc/libs/latest/libs/math/doc/html/math_toolkit/autodiff.html
- “FP64 is All You Need,” NeurIPS 2025 — https://arxiv.org/abs/2505.10949